前言 仅供本人面试前准备,其他人还是别看了,没意义。有很多我缩写,省去了很多易理解的部分。
我尽量找别人已经总结过的东西,而不是自己写,无意义,面试的八股文罢了。都是靠努力就能实现的东西。
常见容器 ArrayList 详解 https://note.youdao.com/ynoteshare1/index.html?id=efd2a3a29d2626acea2b053e56bae5cc&type=notebook#/04F1A0EFF8F241C2A89E2234AAF0A36A
底层基于数组 实现
创建 ArrayList 如果不指定大小 ,会先创建一个大小为 0 的 Object[ ] 数组 ,
第一次添加数据 时,会扩容 成 ArrayList 的 默认大小 default_capacity:10** ;**
创建时如果指定大小 ,直接创建指定大小的Object[ ]数组
add()
对 size+1 ,去判断数组是否满了 ,如果满了就调用 grow()方法扩容 ,扩容大小为,原数组大小 + 原数组大小右移一位 。也就是扩容到原来的1.5倍 。JDK 1.6 是 1.5 倍 +1 ,JDK 1.7,1.8 是 1.5 倍。
然后把老数组拷贝到新数组里
elementData = Arrays.copyOf(elementData, newCapacity);
最后 elementData[ size++ ] = e ,对数组赋值,(并且size+1)
add(index,e)
首先对index做数组越界检查rangeCheck(index) ; 如果越界了,抛数组越界异常
如果没越界,还是对 size + 1,判断是否需要扩容 ,如果需要扩容,调用grow 方法
如果需要扩容,调用System.arraycopy(1,2,3,4,5) 方法。参数解释1:原来的数组,2:从哪里开始复制。3:复制的目标数组。4:目标数组的第几位开始复制。5:一共复制几个数 。
System.arraycopy(elementData, index, elementData, index + 1, size - index);
假设把数字6插入到第3位,复制过后的数组是,1 2 3 4 5 -> 1 2 3 3 4 5
然后再把目标的位置的值修改,变为 1 2 6 3 4 5
最后size++;
set(index,e)
首先解释,set这个方法是替换该位置原来的元素,所以不会使数组变大,不会做扩容判断
然后对index做数组越界检查,如果越界了,抛数组越界异常
把e替换到数组的index位置
返回数组index位置的原始值
remove(index)
首先对index做数组越界检查rangeCheck(index); ,如果越界了,抛数组越界异常
然后进行数组拷贝 System.arraycopy(elementData, index+1, elementData, index,size - index - 1);
假设把第三位数字删除,1 2 3 4 5 6 - > 1 2 4 5 6 6
然后 element[size–] = null; 最后返回被删除的值
get(index)
首先对index做数组越界检查rangeCheck(index); ,如果越界了,抛数组越界异常
return elementData(index);
总结来说,AraayList的get方法效率非常高,直接返回对应下标值,add方法和remove方法,效率就有点低了,需要考虑数组扩容和数组拷贝的问题** 。**
所以ArrayList比较适用于插入操作较少,不是很频繁插入的场景。
HashMap 详解 https://note.youdao.com/ynoteshare1/index.html?id=efd2a3a29d2626acea2b053e56bae5cc&type=notebook#/79C59785226E4D679AF124256055760B
数组加单链表,1.8 后是红黑树
初始容量 16 1 << 4
加载因子 0.75 泊松分布
扩容临界值 = 容量 * 加载因子
容量必须是 2 的 n 次方,就是tableSizeFor方法
构造函数完成后也只是创建一个空数组,只有在第一次放数据时才会初始化容量,等到第一次放数据的时候用。threshold就是这个大小,构造函数阶段会算出这数的值。为什么用这个数保存数组大小,我觉得是作者觉得既然构造阶段数组没有初始化,那临界值也没什么意义,就临时当数组初始大小,等待put的时候给数组初始化,然后那时再回归他本身的意义,扩容临界值。
size是集合当前大小
构造函数三个,无参 16,一个参初始容量,两个参 初始容量和加载因子。
hash 算法:让高位和低位做异或运算,让高位也参与 hash 寻址运算,降低 hash 冲突。
hash 寻址:为什么是 hash 值和数组 length -1 进行与运算?取余效率低,做位运算效率高,所以容量必须是 2 的 n 次方,如果不是,就找最相近的,用 tableSizeFor 方法。
链表超过 8 个后,变红黑树(数组的容量大于等于 64)转成红黑树后,会变成 TreeNode
扩容机制:数组 2 倍扩容,rehash,hash & n-1,判断二进制结果中是否多出一个 bit 的1,如果没多,那么就是原来的index,如果多了出来那么就是 index+oldCap,通过这个方式,避免 rehash,用每个 hash 对新数组.length 取模,1.8 后优化了下,如果一个链表的长度超过了 8,会自动将链表转成红黑树,查找的性能是 O(logn),比 O(n)高。
红黑树是二叉查找树,左小右大,普通的二叉查找树可能出现瘸子的情况,只有一条腿,不平衡,导致查询性能变成 O(n),线性查询。红黑树有一大堆的限制条件。例如
如果破坏了红黑树的规则和平衡,会自动 rebalance,变色(红<–>黑),左旋,右旋之类的。
ps:hashcode是int型,4个字节,一个字节8个bit,一共32位
先定义个变量: key的hashcode右移 16位,其实就是把原来的hashcode值的高16位放到低16位,高16位补0。然后画图讲解:
相当于拿hashcode的低16为和高16位做异或操作(不一样的为1,一样的为0),让高16位也参与到运算中(正常来说集合的大小是不会特别大的,2的16次幂就6万多了,虽然hashmap允许的最大值是2的30次幂),所以,hash值的后16位90%的情况下都不会参与运算。但是现在高16位和低16位异或后,低16位就同时保留了高低两部分的特征,降低hash冲突。
为什么说可以降低hash冲突,因为如果两个key,解析的hashcode可能低16为一样的,但是如果这么异或一下,就不一样了
JDK 1.7 的hashMap 在并发情况下导致死循环的问题,头插法,不同线程的 next 赋值导致链表成环。不同线程,如何计算 Hash 的时候,A 线程时间片用完了,挂起,B 线程看见 table[i] 是空的,直接插入,A 线程因为已经执行完了 Hash 计算,直接进行插入,就会覆盖 B 线程插入的值
JDK 8 用 head 和 tail 来保证链表的顺序和之前一样;JDK 7 rehash 会倒置链表元素)
ConcurrentHashMap
1.7 Segment + 分段数组 + 链表
Segment 继承自 ReetrantLock
弱一致性。当创建迭代器后,其他线程删除了该元素时候并不会抛出java.util.ConcurrentModificationException异常,能够保持创建迭代器后的元素被正确的Iterator.next()出来。例如ConcurrentHashMap就是弱一致性迭代器,HashMap就是强一致性迭代器。
get 无锁,volatile 加在了 Node 上
sizeCtl -1代表有线程完成了初始化;别的负数代表有线程在扩容;初始化完成后,sizeCtl就持有下一次扩容的size,作用即threshOld
LinkedList 详解 自行查看
LinkedList 底层是基双向链表实现的
LinkedList的每条数据都会被封装成 Node
1 2 3 4 5 6 7 8 9 10 11 private static class Node <E > E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this .item = element; this .next = next; this .prev = prev; } }
ArrayBlockingQueue 详解 用数组实现的有界阻塞队列。此队列按照先进先出(FIFO)的原则对元素进行排序。默认情况下 不保证访问者公平的访问队列,所谓公平访问队列是指阻塞的所有生产者线程或消费者线程,当 队列可用时,可以按照阻塞的先后顺序访问队列,即先阻塞的生产者线程,可以先往队列里插入 元素,先阻塞的消费者线程,可以先从队列里获取元素。通常情况下为了保证公平性会降低吞吐 量。我们可以使用以下代码创建一个公平的阻塞队列:
1 ArrayBlockingQueue fairQueue = new ArrayBlockingQueue(1000 ,true );
LinkedBlockingQueue 详解 基于链表的阻塞队列,同 ArrayListBlockingQueue 类似,此队列按照先进先出(FIFO)的原则对 元素进行排序。而 LinkedBlockingQueue 之所以能够高效的处理并发数据,还因为其对于生产者 端和消费者端分别采用了独立的锁来控制数据同步,这也意味着在高并发的情况下生产者和消费 者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。
LinkedBlockingQueue 会默认一个类似无限大小的容量(Integer.MAX_VALUE)。
ConcurrentHashMap详解 1.7分段数组+单向链表
1.8其中抛弃了原有的 Segment 分段锁,而采用了 CAS + synchronized 来保证并发安全性。
https://www.jianshu.com/p/aa017a3ddc40
枚举 从字节码层面上看,枚举仅仅是一个继承于 java.lang.Enum 的类、自动生成了 values 和 valueOf 方法的普通 Java 类而已。
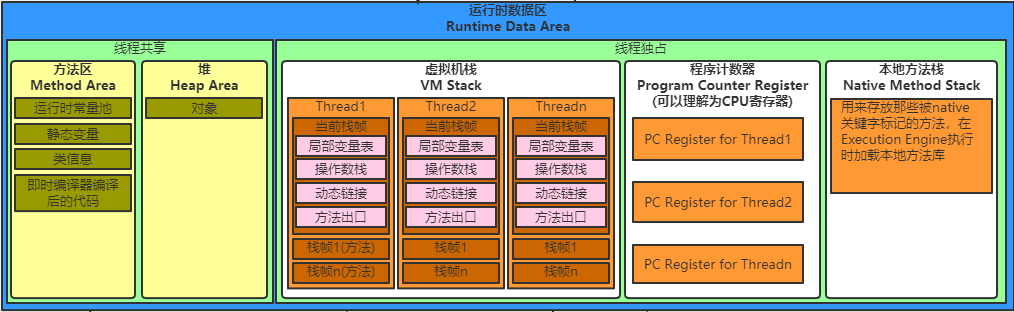
CopyOnWriteArrayList IO NIO Reflect Class Method Constructor ClassLoader JVM 运行时数据区 // 不想自己画,原图片在 https://www.cnblogs.com/wuzhenzhao/p/12346515.html
程序计数器 程序计数器是一块较小的内存空间,它可以看作是当前线程所执行的字节码的行号指示器。在虚拟机的概念模型里面(仅是概念模型,各种虚拟机可能会通过一些更高效的方式去实现),字节码解释工作时就是通过改变这个计数器的值来选去下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程回复等基础功能都需要以来这个计数器来完成。
Java 虚拟机栈 与程序计数器一样,Java虚拟机栈也是线程私有的,它的生命周期与线程相同。虚拟机描述的是Java方法执行的内存模型:每个方法在执行的同时都会创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每一个方法从调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中入栈到出栈的过程。
Java虚拟机栈中还有着局部变量表部分,局部变量表存放了编译期可知的各种基本数据类型(boolean、byte、char、short、int、float、long、doublle)、对象引用(reference类型,它不等同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或其他与此对象相关的位置)和 returnAddress 类型(指向了一条字节码指令的地址)。
其中 64 位长度的 long 和 double 类型的数据会占用 2 个局部变量空间(Slot),其余的数据类型只占用1个。局部变量表所需要的内存空间是完全确定的,在方法运行期间不会改变局部变量表的大小。
在 Java 虚拟机规范中,对这个区域规定了两种异常状况:如果线程请求的栈深度大于虚拟机所允许的深度,将抛出 StackOverflowError 异常;如果虚拟机栈可以动态扩展(当前大部分的Java虚拟机都可动态扩展,只不过 Java 虚拟机规范中也允许固定长度的虚拟机栈)如果扩展是无法申请到足够的内存,就会抛出OOME异常。OutOfMemoryError 后文就简称为 OOME 了。
本地方法栈 本地方法栈(Native Method Stack)与虚拟机栈所发挥的作用是非常相似的,它们之间的区别不过是虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。在虚拟机规范中对本地方法栈中方法使用的语言、使用方式与数据结构并没有强制规定,因此具体的虚拟机可以自由的实现它。甚至有的虚拟机(譬如Sun HotSpot虚拟机)直接就把本地方法栈和虚拟机栈合二为一。与虚拟机栈一样,本地方法栈区域也会抛出 StackOverflowError 和 OOME 异常。
堆 Java 堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存。这一点Java虚拟机规范的描述是:所有的对象实例以及数组都要在堆上分配,JIT,逃逸分析,栈上创建对象。
分代回收,新生代(from+to+Eden,1:1:8)+老年代。从内存分配的角度来看,线程共享Java堆中可能划分出多个线程私有的分配缓冲区。
逻辑上连续内存空间。
方法区(Method Area)与 Java 堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即使编译器后的代码等数据。又名非堆(Non-Heap),1.7 用永久代(Permanent Generation)实现方法区,1.8 更名为 Meta Space。1.7 及以前的版本的项目容易报 Permanent Generation OOM,1.6 默认 82M,1.7 默认 128M,当类和静态变量一多就容易报错,解决办法是加大这块内存地址。
运行时常量池 运行时常量池(Runtime Pool)是方法区的一部分。Class文件中除了有类的版本,字段,方法,接口等描述信息外,还有一项信息是常量池(Constant Pool Table),用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后进入方法区的运行时常量池中存放。
运行时常量是相对于常量来说的,它具备一个重要特征是:动态性。当然,值相同的动态常量与我们通常说的常量只是来源不同,但是都是储存在池内同一块内存区域。Java语言并不要求常量一定只能在编译期产生,运行期间也可能产生新的常量,这些常量被放在运行时常量池中。这里所说的常量包括:基本类型包装类(包装类不管理浮点型,整形只会管理-128到127)和String(也可以通过String.intern()方法可以强制将String放入常量池)。
直接内存 直接内存(Direct Memory)并不是虚拟机运行时数据区的一部分,也不是Java虚拟机规范定义中的内存区域。但那是这部分内存也被频繁地使用,而且也可能异常能导致OOME异常出现,
对象创建
指针碰撞 :假设 Java 堆中内存是绝对规整的,所有内存都放在一遍,空闲的内存放在另一边,中间放一个指针作为分解点的指示器,那所分配内存仅仅是把那个指针向空闲空间那边挪一段与对象大小相等的距离。空闲列表 :因为堆内存在物理上是不连续的,而在逻辑上是连续的。当虚拟机在给对象在堆中分配内存时,会出现不是在连续内存空间上分配的情况。为了让对象能够在堆中能分到内存,虚拟机必须维护一个列表,记录上哪些内存块是可以用的,在分配的时候从列表中找到一块足够大的空间划分给对象实例,并更新列表上的记录。
什么情况会发生 OOM
堆溢出
虚拟机栈和本地方法栈溢出—— 1.请求的栈深度大于虚拟机允许的最大深度,抛出 StackOverflowError。2. 如果虚拟机在扩展栈时无法申请到足够的内存空间,则抛出 OOM。
方法区和运行时常量池溢出——常量池属于方法区的一部分,类太多(包括本身就有的,还有动态生成的类太多)。
本机直接内存溢出—— -XX:MaxDirectMemorySize 指定,不指定,默认和 Java 堆最大值( -Xmx 指定) 一样。
什么时候回收对象 引用计数 你引用我,我引用你,你我都是空对象。就会导致这个引用计数回收不了, Python 就是用的引用计数。
可达性分析算法 GC Roots
虚拟机栈(栈帧中的本地变量表)中引用的对象。
方法区中类静态属性引用的对象。
方法区中常量引用的对象。
本地方法栈中 JNI 应用的对象。
什么时候对象不可达? 第一次标记
第二次标记
经过第一次标记后的对象,根据 此对象是否有必要执行finalize()方法 进行筛选。被判定为确实有必要执行finalize()方法的对象将会被放置在一个名为F-Queue的队列之中。
GC 算法 标记清除(Mark-Sweep) 分为两个阶段,标注和清除。标记阶段标记出所有需要回收的对象,清 除阶段回收被标记的对象所占用的空间,容易产生内存碎片。
复制(copying) 按内存容量将内存划分为等大小的两块。每次只使用其中一块,当这一块内存满后将尚存活的对象复制到另一块上去,把已使用的内存清掉。消耗内存多,但是没有内存碎片产生,用于新生代对象创建。
标记整理(Mark-Compact) 标记后不是清理对象,而是将存活对象移向内存的一端,然后清除端边界外的对象。
和指针碰撞不同
分代收集算法 根据对象存活的不同生命周期将内存划分为不同的域,一般情况下将 GC 堆划分为老生代(Tenured/Old Generation)和新生代(Young Generation)。老生代的特点是每次垃圾回收时只有少量对象需要被回收,新生代的特点是每次垃 圾回收时都有大量垃圾需要被回收,因此可以根据不同区域选择不同的算法。
新生代与复制算法 目前大部分 JVM 的 GC 对于新生代都采取 Copying 算法,因为新生代中每次垃圾回收都要 回收大部分对象,即要复制的操作比较少,但通常并不是按照 1:1 来划分新生代。一般将新生代 划分为一块较大的 Eden 空间和两个较小的 Survivor 空间(From Space, To Space),每次使用 Eden 空间和其中的一块 Survivor 空间,当进行回收时,将该两块空间中还存活的对象复制到另 一块 Survivor 空间中。
老年代与标记复制算法 而老年代因为每次只回收少量对象,因而采用 Mark-Compact 算法。
JAVA 虚拟机提到过的处于方法区的永生代(Permanet Generation),它用来存储 class 类, 常量,方法描述等。对永生代的回收主要包括废弃常量和无用的类。
对象的内存分配主要在新生代的 Eden Space 和 Survivor Space 的 From Space(Survivor 目 前存放对象的那一块),少数情况会直接分配到老生代。
当新生代的 Eden Space 和 From Space 空间不足时就会发生一次 GC,进行 GC 后,Eden Space 和 From Space 区的存活对象会被挪到 To Space,然后将 Eden Space 和 From Space 进行清理。
如果 To Space 无法足够存储某个对象,则将这个对象存储到老生代。
在进行 GC 后,使用的便是 Eden Space 和 To Space 了,如此反复循环。
当对象在 Survivor 区躲过一次 GC 后,其年龄就会+1。默认情况下年龄到达 15 的对象会被 移到老生代中。
Java 四中引用类型 强引用 把一个对象赋给一个引用变量,这个引用变量就是一个强引 用。当一个对象被强引用变量引用时
软引用 软引用需要用 SoftReference 类来实现,对于只有软引用的对象来说,当系统内存足够时它 不会被回收,当系统内存空间不足时它会被回收。软引用通常用在对内存敏感的程序中。
弱引用 弱引用需要用 WeakReference 类来实现,它比软引用的生存期更短,对于只有弱引用的对象 来说,只要垃圾回收机制一运行,不管 JVM 的内存空间是否足够,总会回收该对象占用的内存。
虚引用 虚引用需要 PhantomReference 类来实现,它不能单独使用,必须和引用队列联合使用。虚 引用的主要作用是跟踪对象被垃圾回收的状态。
什么是 Safepoint Safepoint 可以用在不同地方,比如GC、Deoptimization,在Hotspot VM中,GC safepoint比较常见,需要一个数据结构记录每个线程的调用栈、寄存器等一些重要的数据区域里什么地方包含了GC管理的指针。
从线程角度看,safepoint可以理解成是在代码执行过程中的一些特殊位置,当线程执行到这些位置的时候,说明虚拟机当前的状态是安全的,如果有需要,可以在这个位置暂停,比如发生GC时,需要暂停暂停所以活动线程,但是线程在这个时刻,还没有执行到一个安全点,所以该线程应该继续执行,到达下一个安全点的时候暂停,等待GC结束。
https://www.jianshu.com/p/c79c5e02ebe6
Minor GC 和 Full GC 的触发机制 新生代 GC(Minor GC) 指发生在新生代的垃圾收集动作,因为 Java 对象大多都具备朝生夕灭的特性,所以 Minor GC 非常频繁,一般回收速度也比较快。
老年代 GC(Major GC/Full GC) 指发生在老年代的 GC,出现了 Major GC,经常会伴随着至少一次的 Minor GC(但非绝对的,在 Parallel Scavenge 收集器的收集策略里就有直接进行 Major GC 的策略选择过程)。Major GC 的速度一般会比 Minor GC 慢 10 倍以上。
JVM 系列文章之 Full GC 和 Minor GC
设置参数,可让创建对象时,直接进入old区。
如果对象在 Eden 区出生并经过第一次 Minor GC 后仍然存活,并且能够被 Surviror 容纳的话,将被一定到 Survivor 空间中,并且对象年龄设为 1。对象在 Survivor 中每“熬”过一次 Minor GC,年龄+1,默认到 15 就晋升到老年代。但并不是永远要求对象年龄必须达到那个参数,如果在 Survivor 空间中相同年龄所有对象的大小的总和大于 Survivor 空间的一半,年龄大于或等于该年龄的对象就可以直接进入老年代。
-XX:MaxTenuringThreshold=15 CMS里面默认是6。
内存分配以及回收 对象优先在 Eden 区分配 大多数情况下,对象优先在 Eden 区中分配。当 Eden 区没有足够空间进行分配时,虚拟机将发起一次 Minor GC。
大对象为什么直接进入老年代 虚拟机提供了一个-XX:PretenureSizeThreshold参数,不同垃圾收集器默认值不同,直接在 Eden 区。大于这个设置值的对象直接在老年代分配。这样做的目的是避免在Eden区及两个Survivor区(from区to区)之间发生大量的内存复制。不同分代,采用不同垃圾回收算法,young 区采用的是复制清除算法,如果是大对象,就得不偿失了。
注意:PretenureSizeThreshold参数只对Serial和ParNew两款收集器有效,Parallel Scavenge收集器不认识这个参数,Parallel Scavenge收集器一般并不需要设置。如果遇到必须使用此参数的场合,可以考虑ParNew加CMS的收集器组合。
一个简单的方法,在 Spring Boot项目中写个 循环依赖类(需要特殊处理,在我的 github 上的一个项目中有),然后用 类层次 类去引用,再Debug,就能看见 栈溢出信息,和 from to区的信息。
空间分配担保 在发生 Minor GC 之前,虚拟机会先检查老年代最大可用的连续空间是否大于新生代所有对象总空间,如果是,Minor GC 确保安全。看 HandlePromotionFailure 是否允许担保失败。如果允许,会继续检查老年代最大可用的连续空间是否大于历次晋升到老年代对象的平均大小,如果大于,将尝试进行一次 Minor GC,尽管这次 Minor GC 有风险,如果小于或者配置的不允许,那么就改成一次 Full GC。
JVM 调优
-Xms -Xmx 设置成一样 。例如 -Xms2048M -Xmx2048M
-XX:USEBAISEDLOCKED=FALSE 关闭偏向锁。JDK 1.6引入新概念,在线程竞争不激烈时引入,偏向锁,轻量级锁。支持锁的升级和降级,但并发比较大的环境下,关掉这个是好的选择。在对象头中标出,00,01,10,11,两位标出是什么状态。
年轻代:-XX:+UseParNewGC。
老年代:-XX:+UseConcMarkSweepGC。
-XX:-DoEscapeAnalysis : 表示关闭逃逸分析 从jdk 1.7开始已经默认开始逃逸分析,如需关闭,需要指定-XX:-DoEscapeAnalysis。逃逸分析是让某些朝生夕死的对象,在栈上创建对象,随着栈的消亡而消亡。
https://www.hollischuang.com/archives/2583
频繁触发 Full GC ,如果使用的是 G1,可以加上 -XX:+PrintAdaptiveSizePolicy 参数,查看到底是谁引发的
更多见 https://www.oracle.com/technetwork/tutorials/tutorials-1876574.html。比如你用的是 Azkaban,这种朝生夕死的任务执行的项目,它默认的配置是很简单的,也是很坑的。我的建议是把下面的调整到 5、5。当然,这个我也只是简单测了,改成这样后,就没有之前的 OOM 问题了。更好的比例,需要你一遍遍调。
-XX:NewRatio=n
Ratio of new/old generation sizes. The default value is 2.
-XX:SurvivorRatio=n
Ratio of eden/survivor space size. The default value is 8.
类加载 加载过程
https://www.cnblogs.com/straybirds/p/8513870.html
什么时候加载,虚拟机规范没强制要求,这点虚拟机自己发挥,但是初始化阶段,虚拟机规范严格规定了有且仅有 5 种情况必须立即对类进行初始化。
遇到 new、getstatic、putstatic 或 invokestatic 这 4 条字节码指令时。new 对象,读取或者设置一个类的静态字段(非 final 修饰、已在编译期把结果放入常量池的静态字段除外)的时候,调用静态方法的时候。
使用 java.lang.reflect 包的方法对类进行反射调用的时候。没有初始化,则要。
当初始化一个类的时候,如果其父类未被初始化,则需要先触发其父类的初始化。
当虚拟机启动时,用户需要指定一个需要执行的主类。(main 方法)
当使用 JDK 1.7 的动态语言支持时,如果一个 java.lang.invoke.MethodHandle 实例最后的解析结果 REF_getStatic、REF_putStatic、REF_invokeStatic 的方法句柄,并且这个方法的句柄所对应的类没有进行过初始化,则需要先出发其初始化。
双亲委派模型
Bootstrap ClassLoader(C++ 实现,负责将存放在 <JAVA_HOME>\lib目录中的,或者被 -Xbootclasspath 参数所指定的路径中的,并且是虚拟机识别的仅按照文件名识别,例如 rt.jar 名字不符合也不会加载。加载到虚拟机的内存中。返回 null 就能用这个加载器加载)
Extension ClassLoader(Java 实现负责加载 <JAVA_HOME>\lib\ext目录中的,或者被 java.ext.dirs 系统变量所指定的路径中的所有类库,开发者可以直接用)
Application ClassLoader(Java 实现 一般情况下,这个就是默认的类加载器)
自定义 ClassLoader
破坏双委派模型 自己覆盖 loadClass 。OSGi 给“高速奔跑的汽车换轮胎”。还有公司要求会这个。。。。
虚拟机字节码执行引擎
局部变量表
动态连接
方法返回地址
操作数栈
方法调用
解析
分派
动态类型语言支持
这个就是方法调用就是压栈,舍弃当前栈帧就是返回上一个方法。Debug 的 drop frame。
程序源码 -> 语法解析 -> 单词流 -> 语法解析 -> 抽象语法树
二选一
-> 指令流 -> 解释器 -> 解释执行
-> 优化器 -> 中间代码 -> 生成器 -> 目标代码
JVM 各种优化 编译优化 例如
1 2 3 4 String a = "Foo" + "Bar" ; String b = "FooBar" ; System.out.println(a == b);
运行优化
JMM https://zhuanlan.zhihu.com/p/29881777
无非就是搞了个抽象,具体实现,不同虚拟机不同的来。
多线程 volatile 如何保证内存可见性 volatile 是 Java 提供的轻量级同步机制
MESI 协议 MESI 协议 是一个基于失效的缓存一致性 协议,是支持回写(write-back)缓存的最常用协议。也称作伊利诺伊协议 (Illinois protocol,因为是在伊利诺伊大学厄巴纳-香槟分校 被发明的[1] )。与写通过(write through)缓存相比,回写缓冲能节约大量带宽。总是有“脏”(dirty)状态表示缓存中的数据与主存中不同。MESI协议要求在缓存不命中(miss)且数据块在另一个缓存时,允许缓存到缓存的数据复制。与MSI协议 相比,MESI协议减少了主存的事务数量。这极大改善了性能。[2]
JMM(Java Memory Model)本身是一种抽象的概念,并不真实存在,它描述的一组规则或规范,通过这组规范定义了程序中各个变量(含实例字段,静态字段和构成数组对象的元素)的访问方式。
JMM关于同步的规定:
线程解锁前必须把共享变量的值刷新回主存
线程加锁前,必须读取主存的最新值到自己的工作内存
加锁解锁是同一把锁
更多https://blog.csdn.net/t894690230/article/details/50588129
happens-before
程序次序法则:如果在程序中,所有动作 A 出现在动作 B 之前,则线程中的每动作 A 都 happens-before 于该线程中的每一个动作 B。
监视器锁法则:对一个监视器的解锁 happens-before 于每个后续对同一监视器的加锁。
volatile 变量法则:对 volatile 域的写入操作 happens-before 于每个后续对同一 volatile 的读操作。
传递性:如果 A happens-before 于 B,且 B happens-before C,则 A happens-before C。
https://juejin.im/post/5ae6d309518825673123fd0e
https://en.wikipedia.org/wiki/Happened-before
Synchronized C++ 实现源码解析 自旋锁的定义:当一个线程尝试去获取某一把锁的时候,如果这个锁此时已经被别人获取(占用),那么此线程就无法获取到这把锁,该线程将会等待,间隔一段时间后会再次尝试获取。这种采用循环加锁 -> 等待的机制被称为自旋锁(spinlock)。
因为自旋锁避免了操作系统进程调度和线程切换,所以自旋锁通常适用在时间比较短的情况下。由于这个原因,操作系统的内核经常使用自旋锁。但是,如果长时间上锁的话,自旋锁会非常耗费性能,它阻止了其他线程的运行和调度。线程持有锁的时间越长,则持有该锁的线程将被 OS(Operating System) 调度程序中断的风险越大。如果发生中断情况,那么其他线程将保持旋转状态(反复尝试获取锁),而持有该锁的线程并不打算释放锁,这样导致的是结果是无限期推迟,直到持有锁的线程可以完成并释放它为止。
解决上面这种情况一个很好的方式是给自旋锁设定一个自旋时间,等时间一到立即释放自旋锁。自旋锁的目的是占着CPU资源不进行释放,等到获取锁立即进行处理。但是如何去选择自旋时间呢?如果自旋执行时间太长,会有大量的线程处于自旋状态占用 CPU 资源,进而会影响整体系统的性能。因此自旋的周期选的额外重要!JDK在1.6 引入了适应性自旋锁,适应性自旋锁意味着自旋时间不是固定的了,而是由前一次在同一个锁上的自旋时间以及锁拥有的状态来决定,基本认为一个线程上下文切换的时间是最佳的一个时间。
synchronized.cpp解析
Jdk1.6 锁的升级与降级,自旋锁->偏向锁->轻量级锁->重量级锁(操作系统内核的 mutex lock)
ReentrantLock 和 synchronized 之间 在加锁和内存上提供的语义与内置锁相同,此外它还提供了可定时、可中断、可轮询、公平性,以及实现非块结构的加锁。只要在需要这些高级的功能时,用 ReentrantLock,否则还是应该优先使用 synchronized。
ThreadLocal https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/Multithread/ThreadLocal.md
Spring MVC 中,RequestHolder 使用 ThreadLocal 进行 HttpServletRequest 进行缓存。还有事务,AopProxyHolder、MyBatis 的 PageHelper 这种,都是根据当前线程的变量来确定的。
AQS https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/Multithread/AQS.md
Doug Lea 设计的,CountDownLatch、ReentrantLock 都继承这个类,是 Java 最低层级的同步机制。
AQS 是一个用来构建锁和同步器的框架,使用 AQS 能简单且高效地构造出应用广泛的大量的同步器。
AQS 原理概览 AQS 核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制 AQS 是用 CLH 队列锁实现的,即将暂时获取不到锁的线程加入到队列中。
volatile 变量 + 双向队列。
AQS 对资源的共享方式
Exclusive(独占)
只有一个线程能执行,如 ReentrantLock。又可分为公平锁和非公平锁,ReentrantLock 同时支持两种锁,下面以 ReentrantLock 对这两种锁的定义做介绍:
公平锁:按照线程在队列中的排队顺序,先到者先拿到锁
非公平锁:当线程要获取锁时,先通过两次 CAS 操作去抢锁,如果没抢到,当前线程再加入到队列中等待唤醒。
Share(共享)
多个线程可同时执行,如 Semaphore/CountDownLatch。Semaphore、CountDownLatCh、 CyclicBarrier、ReadWriteLock 我们都会在后面讲到。
ReentrantReadWriteLock 可以看成是组合式,因为 ReentrantReadWriteLock 也就是读写锁允许多个线程同时对某一资源进行读。
不同的自定义同步器争用共享资源的方式也不同。自定义同步器在实现时只需要实现共享资源 state 的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败入队/唤醒出队等),AQS 已经在上层已经帮我们实现好了。
Fork/Join https://time.geekbang.org/column/article/92524
Fork/Join 是一个并行计算的框架,主要就是用来支持分治任务模型的,这个计算框架里的 Fork 对应的是分治任务模型里的任务分解,Join 对应的是结果合并。Fork/Join 计算框架主要包含两部分,一部分是分治任务的线程池 ForkJoinPool,另一部分是分治任务 ForkJoinTask。这两部分的关系类似于 ThreadPoolExecutor 和 Runnable 的关系,都可以理解为提交任务到线程池,只不过分治任务有自己独特类型 ForkJoinTask。
ForkJoinTask 是一个抽象类,它的方法有很多,最核心的是 fork() 方法和 join() 方法,其中 fork() 方法会异步地执行一个子任务,而 join() 方法则会阻塞当前线程来等待子任务的执行结果。ForkJoinTask 有两个子类——RecursiveAction 和 RecursiveTask,通过名字你就应该能知道,它们都是用递归的方式来处理分治任务的。这两个子类都定义了抽象方法 compute(),不过区别是 RecursiveAction 定义的 compute() 没有返回值,而 RecursiveTask 定义的 compute() 方法是有返回值的。这两个子类也是抽象类,在使用的时候,需要你定义子类去扩展。
Fork/Join 并行计算的核心组件是 ForkJoinPool。ForkJoinPool 本质上也是一个生产者 - 消费者的实现,但是更加智。ThreadPoolExecutor 内部只有一个任务队列,而 ForkJoinPool 内部有多个任务队列,当我们通过 ForkJoinPool 的 invoke() 或者 submit() 方法提交任务时,ForkJoinPool 根据一定的路由规则把任务提交到一个任务队列中,如果任务在执行过程中会创建出子任务,那么子任务会提交到工作线程对应的任务队列中。
如果工作线程对应的任务队列空了,是不是就没活儿干了呢?不是的,ForkJoinPool 支持一种叫做“任务窃取”的机制,如果工作线程空闲了,那它可以“窃取”其他工作任务队列里的任务,例如下图中,线程 T2 对应的任务队列已经空了,它可以“窃取”线程 T1 对应的任务队列的任务。如此一来,所有的工作线程都不会闲下来了。ForkJoinPool 中的任务队列采用的是双端队列,工作线程正常获取任务和“窃取任务”分别是从任务队列不同的端消费,这样能避免很多不必要的数据竞争。我们这里介绍的仅仅是简化后的原理,ForkJoinPool 的实现远比我们这里介绍的复杂
Fork/Join 并行计算框架主要解决的是分治任务。分治的核心思想是“分而治之”:将一个大的任务拆分成小的子任务去解决,然后再把子任务的结果聚合起来从而得到最终结果。这个过程非常类似于大数据处理中的 MapReduce,所以你可以把 Fork/Join 看作单机版的 MapReduce。
Fork/Join 并行计算框架的核心组件是 ForkJoinPool。ForkJoinPool 支持任务窃取机制,能够让所有线程的工作量基本均衡,不会出现有的线程很忙,而有的线程很闲的状况,所以性能很好。Java 1.8 提供的 Stream API 里面并行流也是以 ForkJoinPool 为基础的。不过需要你注意的是,默认情况下所有的并行流计算都共享一个 ForkJoinPool,这个共享的 ForkJoinPool 默认的线程数是 CPU 的核数;如果所有的并行流计算都是 CPU 密集型计算的话,完全没有问题,但是如果存在 I/O 密集型的并行流计算,那么很可能会因为一个很慢的 I/O 计算而拖慢整个系统的性能。所以建议用不同的 ForkJoinPool 执行不同类型的计算任务。
死锁 一组互相竞争资源的线程因互相等待,导致“永久”阻塞的现象。线程 A 有🔒 1,我还想获取🔒 2,但是另一个线程 B 持有🔒 2,两个线程都不释放锁,等着对方释放锁,就会导致死锁。一般死锁了,只能重启。
死锁发生的条件
互斥,共享资源 X 和 Y 只能被一个线程占用;
占有且等待,线程 T1 已经取得共享资源 X,在等待共享资源 Y 的时候,不释放共享资源 X;
不可抢占,其他线程不能强行抢占线程 T1 占有的资源;
循环等待,线程 T1 等待线程 T2 占有的资源,线程 T2 等待线程 T1 占有的资源,就是循环等待。
破坏其中一个,就可以成功避免死锁的发生。
CAS 全称是 Compare And Swap,即“比较并交换。
CAS 指令包含 3 个参数:共享变量的内存地址 A、用于比较的值 B 和共享变量的新值 C;并且只有当内存中地址 A 处的值等于 B 时,才能将内存中地址 A 处的值更新为新值 C。作为一条 CPU 指令,CAS 指令本身是能够保证原子性的。
ABA 问题,加版本号。
AtomicInteger 调用 Unsafe 的 compareAndSwap native 方法 1 2 3 public final boolean compareAndSet (int expect, int update) return unsafe.compareAndSwapInt(this , valueOffset, expect, update); }
native 方法 compareAndSwapInt 在 Linux 下的 JDK 实现如下。 1 2 3 4 5 6 UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapInt(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jint e, jint x)) UnsafeWrapper("Unsafe_CompareAndSwapInt" ); oop p = JNIHandles::resolve(obj); jint* addr = (jint *) index_oop_from_field_offset_long(p, offset); return (jint)(Atomic::cmpxchg(x, addr, e)) == e; UNSAFE_END
Atocmic::cmpxchg 在 x86 处理器架构下(Linux 下)的 JDK 实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 > What I'm a bit uncertain about here is which barriers we need and which are optimal as it seems to be a bit different for different ARM versions, maybe somebody can enlighten me? Also I'm not sure how hotspot checks ARM version to make the appropriate decision. > > The proposed x86 implementation is much more straight forward (bsd, linux): > > inline jbyte Atomic::cmpxchg(jbyte exchange_value, volatile jbyte* dest, jbyte compare_value) { > int mp = os::is_MP(); > jbyte result; > __asm__ volatile (LOCK_IF_MP(%4) "cmpxchgb %1,(%3)" > : "=a" (result) > : "q" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp) > : "cc", "memory"); > return result; > } > >>> The implementation of single byte Atomic::cmpxchg on x86 (and all other >>> platforms) emulates the single byte cmpxchgb instruction using a loop of >>> jint-sized load and cmpxchgl and code to dynamically align the destination >>> address. >>> >>> This code is used for GC-code related to remembered sets currently. >>> >>> I have the changes on my platform (amd64, bsd) to simply use the native >>> cmpxchgb instead but could provide a patch fixing this unnecessary >>> performance glitch for all supported x86 if anybody wants this? >> >> I think that sounds good. >> Would you mind looking at other cpu arches to see if they provide something >> similar? It's ok if you can't build the code for the other arches, I can help >> you with that. >> >> /Mikael
ThreadPoolExecutor 配置 ThreadPoolExecutor 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 public ThreadPoolExecutor (int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) if (corePoolSize < 0 || maximumPoolSize <= 0 || maximumPoolSize < corePoolSize || keepAliveTime < 0 ) throw new IllegalArgumentException(); if (workQueue == null || threadFactory == null || handler == null ) throw new NullPointerException(); this .acc = System.getSecurityManager() == null ? null : AccessController.getContext(); this .corePoolSize = corePoolSize; this .maximumPoolSize = maximumPoolSize; this .workQueue = workQueue; this .keepAliveTime = unit.toNanos(keepAliveTime); this .threadFactory = threadFactory; this .handler = handler; }
corePoolSize —— 线程池的目标大小,即在没有任务执行时线程池的大小,并且只有在工作队列满了的情况下才会创建超过这个数量的线程。在 ThreadPoolExecutor 初期,线程并不会立即启动,而是等到有任务提交时才会启动,除非调用 prestartAllThreads。
maximumPoolSize —— 线程池最大值。 the maximum number of threads to allow in the pool。
keepAliveTime —— 当线程数超过核心线程数时,这是多余的空闲线程将在终止之前等待新任务的最长时间。 when the number of threads is greater than the core, this is the maximum time that excess idle threads will wait for new tasks before terminating.
unit —— 上面的时间单位the time unit for the {@code keepAliveTime} argument
workQueue —— 任务队列,这个是提交的任务队列,如果提交的任务大于最大线程数了,会优先放到这个任务队列中。 the queue to use for holding tasks before they are executed. This queue will hold only the {@code Runnable} tasks submitted by the {@code execute} method.
threadFactory —— 利用 ThreadFactory#newThread 来创建 Thread,这里可以对 Thread 进行命名。the factory to use when the executor creates a new thread.
handler —— 执行不了了,wokerqueue 都塞不下了,就执行拒绝策略。可以自定义,用来重试任务,默认是直接丢掉。JDK 提供了 4 种。the handler to use when execution is blocked because the thread bounds and queue capacities are reached
ThreadPoolExecutor 允许提供一个 Blocking Queue 来保存等待执行的任务。
无界队列。LinkedBlockingQueue 默认的构造器就是无界的。public LinkedBlockingQueue() { this(Integer.MAX_VALUE);}
有界队列。ArrayBlockingQueue、有界的 LinkedBlockingQueue、PriorityBlockingQueue。
同步移交。Synchronous Handoff。
无界队列将不会执行拒绝策略,当然如果你的线程数大于了 Integer.MAX_VALUE 还是会执行的,前提是你到达这么多。一般情况就 OOM 了。所以《阿里巴巴 Java 开发规范》中不使用 Executors 创建线城池。
饱和策略
AbortPolicy:中止策略是默认的饱和策略,该策略将抛出未检查的 RejectedExecutionException 调用者可以捕获这个异常,然后根据需求编写自己的处理代码。
DiscardPolicy:当新提交的任务无法保存到队列中等待执行时,抛弃策略会悄悄抛弃该任务。
CallerRunsPolicy:调用者运行(Caller-Runs)策略实现了一种调节机制,该策略既不会抛弃任务,也不会抛弃异常,而是将某些任务回退到调用者,从而降低新任务的流量。它不会在线程池的某个线程中执行新提交的任务,而是在一个调用了 execute 的线程中执行该任务。
DiscardOldestPolicy:抛弃最旧的(Discard-Oldest)策略则会抛弃下一个将被执行的任务,然后尝试重新提交新的任务。如果工作队列是一个优先队列,那么”抛弃最旧的“策略将导致抛弃优先级最高的任务,因此最好不要将“抛弃最旧的”饱和策略和优先级队列放在一起使用。
SynchronousQueue 对于非常大的或者无界的线程池,可以通过使用 SynchronousQueue 来避免任务排队,以及直接将任务从生产者移交给工作者线程。SynchronousQueque 不是一个真正的队列,而是一种在线程之间进行移交的机制。要将一个元素放入 SynchronousQueue 中,必须有另一个线程正在等待接受这个元素。如果没有线程正在等待,并且线程池的当前大小小于最大值,那么 ThreadPoolExecutor 将创建一个新的线程,否则根据饱和策略,这个任务将被拒绝。
ThreadFactory 许多情况下都需要使用定制的线程工厂方法。
例如,为线程池中的线程制定一个 UncaughtExceptionHandler,或者实例化一个定制的 Thread 类用于执行调试信息的记录。线程优先级(其实执行的时候优先级只是个参考),或者守护状态(也不建议),最常用的其实就是取个名字 。
Pivatol 团队就封装了个 NamedThreadFactory,简单的封装,简单的应用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package io.micrometer.core.instrument.util;public class NamedThreadFactory implements ThreadFactory private final AtomicInteger sequence = new AtomicInteger(1 ); private final String prefix; public NamedThreadFactory (String prefix) this .prefix = prefix; } public Thread newThread (Runnable r) Thread thread = new Thread(r); int seq = this .sequence.getAndIncrement(); thread.setName(this .prefix + (seq > 1 ? "-" + seq : "" )); if (!thread.isDaemon()) { thread.setDaemon(true ); } return thread; } }
SpringBoot 相关的监控解决方案从 SpringBoot 2.0开始全面更改为Micrometer,不过要知道 Micrometer 与 Spring 属于同门,都是Pivotal旗下的产品。
扩展 ThreadPoolexecutor
beforeExecute
afterExecutor
terminated
添加日志、计时、监视或统计信息收集的功能。无论任务是从 run 中正常返回,还是抛出一个异常而返回,afterExecute 都会被调用。如果是一个 Error 就不会。如果 beforeExecute 抛出一个 RuntimeException,那么任务将不被执行,并且 afterExecute 也不会被调用。
在线程池完成关闭操作时调用 terminated,也就是在所有任务都已经完成并且所有工作者线程也已经关闭后。terminated 可以用来释放Executor 在其生命周期里分配的各种资源,此外还可以执行发送通知、记录日志或者收集 finalize 统计信息等操作。
Servlet 容器 Tomcat Jetty Websphere Application Server IBM
Nginx Nginx 服务器 Nginx 集群搭建 引入虚拟 IP,keepalived
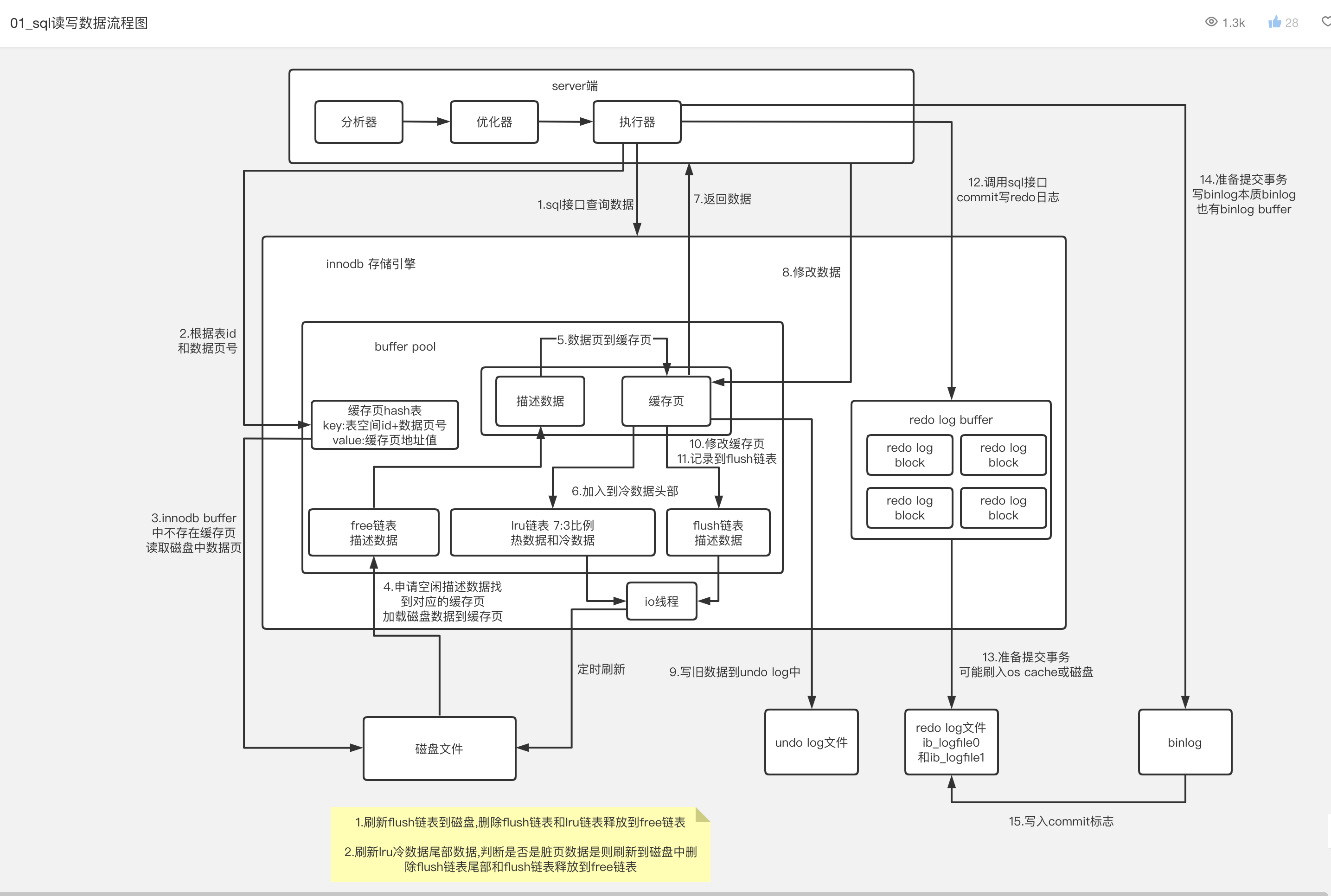
MySQL MySQL 执行过程 那些索引 Spring Spring Bean 的加载过程 Spring Bean 元信息配置阶段
基于 XML、Properties 配置
XMLBeanDefinitionReader#loadBeanDefinitions(String resourceUrl);
BeanDefinitionReader 的实现类 AbstractBeanDefinitionReader,而 AbstractBeanDefinitionReader 有三个实现类。分别对应 XML、Properties、Groovy 文件读取方式。现在都不推荐用这几个。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 package org.springframework.beans.factory.support;import org.springframework.beans.factory.BeanDefinitionStoreException;import org.springframework.core.io.Resource;import org.springframework.core.io.ResourceLoader;import org.springframework.lang.Nullable;public interface BeanDefinitionReader BeanDefinitionRegistry getRegistry () ; @Nullable ResourceLoader getResourceLoader () ; @Nullable ClassLoader getBeanClassLoader () ; BeanNameGenerator getBeanNameGenerator () ; int loadBeanDefinitions (Resource var1) throws BeanDefinitionStoreException int loadBeanDefinitions (Resource... var1) throws BeanDefinitionStoreException int loadBeanDefinitions (String var1) throws BeanDefinitionStoreException int loadBeanDefinitions (String... var1) throws BeanDefinitionStoreException } public abstract class AbstractBeanDefinitionReader implements BeanDefinitionReader , EnvironmentCapable protected final Log logger = LogFactory.getLog(this .getClass()); private final BeanDefinitionRegistry registry; @Nullable private ResourceLoader resourceLoader; @Nullable private ClassLoader beanClassLoader; private Environment environment; private BeanNameGenerator beanNameGenerator = new DefaultBeanNameGenerator(); protected AbstractBeanDefinitionReader (BeanDefinitionRegistry registry) Assert.notNull(registry, "BeanDefinitionRegistry must not be null" ); this .registry = registry; if (this .registry instanceof ResourceLoader) { this .resourceLoader = (ResourceLoader)this .registry; } else { this .resourceLoader = new PathMatchingResourcePatternResolver(); } if (this .registry instanceof EnvironmentCapable) { this .environment = ((EnvironmentCapable)this .registry).getEnvironment(); } else { this .environment = new StandardEnvironment(); } } public int loadBeanDefinitions (Resource... resources) throws BeanDefinitionStoreException Assert.notNull(resources, "Resource array must not be null" ); int count = 0 ; Resource[] var3 = resources; int var4 = resources.length; for (int var5 = 0 ; var5 < var4; ++var5) { Resource resource = var3[var5]; count += this .loadBeanDefinitions((Resource)resource); } return count; } public int loadBeanDefinitions (String location) throws BeanDefinitionStoreException return this .loadBeanDefinitions(location, (Set)null ); } public int loadBeanDefinitions (String location, @Nullable Set<Resource> actualResources) throws BeanDefinitionStoreException ResourceLoader resourceLoader = this .getResourceLoader(); if (resourceLoader == null ) { throw new BeanDefinitionStoreException("Cannot load bean definitions from location [" + location + "]: no ResourceLoader available" ); } else { int count; if (resourceLoader instanceof ResourcePatternResolver) { try { Resource[] resources = ((ResourcePatternResolver)resourceLoader).getResources(location); count = this .loadBeanDefinitions(resources); if (actualResources != null ) { Collections.addAll(actualResources, resources); } if (this .logger.isTraceEnabled()) { this .logger.trace("Loaded " + count + " bean definitions from location pattern [" + location + "]" ); } return count; } catch (IOException var6) { throw new BeanDefinitionStoreException("Could not resolve bean definition resource pattern [" + location + "]" , var6); } } else { Resource resource = resourceLoader.getResource(location); count = this .loadBeanDefinitions((Resource)resource); if (actualResources != null ) { actualResources.add(resource); } if (this .logger.isTraceEnabled()) { this .logger.trace("Loaded " + count + " bean definitions from location [" + location + "]" ); } return count; } } } public int loadBeanDefinitions (String... locations) throws BeanDefinitionStoreException Assert.notNull(locations, "Location array must not be null" ); int count = 0 ; String[] var3 = locations; int var4 = locations.length; for (int var5 = 0 ; var5 < var4; ++var5) { String location = var3[var5]; count += this .loadBeanDefinitions(location); } return count; } }
1 public void registerBeanDefinition (String beanName, BeanDefinition beanDefinition) throws BeanDefinitionStoreException
一般是这个 GenericBeanDefinition 类,不管你是什么类,在我这,都叫 BeanDefinition ,而且在后面会有个 Merge 过程,将所有 BeanDefinition 再次转换成 RootBeanDefinition 然后命名为 mbd 进行各种操作。
Spring Bean 元信息解析阶段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 public class AnnotatedBeanDefinitionReader private final BeanDefinitionRegistry registry; private BeanNameGenerator beanNameGenerator; private ScopeMetadataResolver scopeMetadataResolver; private ConditionEvaluator conditionEvaluator; public AnnotatedBeanDefinitionReader (BeanDefinitionRegistry registry) this (registry, getOrCreateEnvironment(registry)); } public AnnotatedBeanDefinitionReader (BeanDefinitionRegistry registry, Environment environment) this .beanNameGenerator = new AnnotationBeanNameGenerator(); this .scopeMetadataResolver = new AnnotationScopeMetadataResolver(); Assert.notNull(registry, "BeanDefinitionRegistry must not be null" ); Assert.notNull(environment, "Environment must not be null" ); this .registry = registry; this .conditionEvaluator = new ConditionEvaluator(registry, environment, (ResourceLoader)null ); AnnotationConfigUtils.registerAnnotationConfigProcessors(this .registry); } public void register (Class<?>... annotatedClasses) Class[] var2 = annotatedClasses; int var3 = annotatedClasses.length; for (int var4 = 0 ; var4 < var3; ++var4) { Class<?> annotatedClass = var2[var4]; this .registerBean(annotatedClass); } } public void registerBean (Class<?> annotatedClass) this .doRegisterBean(annotatedClass, (Supplier)null , (String)null , (Class[])null ); } public <T> void registerBean (Class<T> annotatedClass, @Nullable Supplier<T> instanceSupplier) this .doRegisterBean(annotatedClass, instanceSupplier, (String)null , (Class[])null ); } public <T> void registerBean (Class<T> annotatedClass, String name, @Nullable Supplier<T> instanceSupplier) this .doRegisterBean(annotatedClass, instanceSupplier, name, (Class[])null ); } public void registerBean (Class<?> annotatedClass, Class<? extends Annotation>... qualifiers) this .doRegisterBean(annotatedClass, (Supplier)null , (String)null , qualifiers); } public void registerBean (Class<?> annotatedClass, String name, Class<? extends Annotation>... qualifiers) this .doRegisterBean(annotatedClass, (Supplier)null , name, qualifiers); } <T> void doRegisterBean (Class<T> annotatedClass, @Nullable Supplier<T> instanceSupplier, @Nullable String name, @Nullable Class<? extends Annotation>[] qualifiers, BeanDefinitionCustomizer... definitionCustomizers) AnnotatedGenericBeanDefinition abd = new AnnotatedGenericBeanDefinition(annotatedClass); if (!this .conditionEvaluator.shouldSkip(abd.getMetadata())) { abd.setInstanceSupplier(instanceSupplier); ScopeMetadata scopeMetadata = this .scopeMetadataResolver.resolveScopeMetadata(abd); abd.setScope(scopeMetadata.getScopeName()); String beanName = name != null ? name : this .beanNameGenerator.generateBeanName(abd, this .registry); AnnotationConfigUtils.processCommonDefinitionAnnotations(abd); int var10; int var11; if (qualifiers != null ) { Class[] var9 = qualifiers; var10 = qualifiers.length; for (var11 = 0 ; var11 < var10; ++var11) { Class<? extends Annotation> qualifier = var9[var11]; if (Primary.class == qualifier) { abd.setPrimary(true ); } else if (Lazy.class == qualifier) { abd.setLazyInit(true ); } else { abd.addQualifier(new AutowireCandidateQualifier(qualifier)); } } } BeanDefinitionCustomizer[] var13 = definitionCustomizers; var10 = definitionCustomizers.length; for (var11 = 0 ; var11 < var10; ++var11) { BeanDefinitionCustomizer customizer = var13[var11]; customizer.customize(abd); } BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(abd, beanName); definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this .registry); BeanDefinitionReaderUtils.registerBeanDefinition(definitionHolder, this .registry); } } }
这里你都用 Java API 方式配置了,一定有 BeanDefition 配置了。
Spring Bean 注册阶段 DefaultListableBeanFactory 实现了 BeanDefinitionRegistry 。它还有其他的实现类,关于 XML 、注解、Groovy、Reactive(响应式的,Josh Long 在 19年推特上有置顶 《Reactive Spring》)、还有其他的 GenericApplicationContext。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 public void registerBeanDefinition (String beanName, BeanDefinition beanDefinition) throws BeanDefinitionStoreException Assert.hasText(beanName, "Bean name must not be empty" ); Assert.notNull(beanDefinition, "BeanDefinition must not be null" ); if (beanDefinition instanceof AbstractBeanDefinition) { try { ((AbstractBeanDefinition)beanDefinition).validate(); } catch (BeanDefinitionValidationException var9) { throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName, "Validation of bean definition failed" , var9); } } BeanDefinition existingDefinition = (BeanDefinition)this .beanDefinitionMap.get(beanName); if (existingDefinition != null ) { if (!this .isAllowBeanDefinitionOverriding()) { throw new BeanDefinitionOverrideException(beanName, beanDefinition, existingDefinition); } if (existingDefinition.getRole() < beanDefinition.getRole()) { if (this .logger.isInfoEnabled()) { this .logger.info("Overriding user-defined bean definition for bean '" + beanName + "' with a framework-generated bean definition: replacing [" + existingDefinition + "] with [" + beanDefinition + "]" ); } } else if (!beanDefinition.equals(existingDefinition)) { if (this .logger.isDebugEnabled()) { this .logger.debug("Overriding bean definition for bean '" + beanName + "' with a different definition: replacing [" + existingDefinition + "] with [" + beanDefinition + "]" ); } } else if (this .logger.isTraceEnabled()) { this .logger.trace("Overriding bean definition for bean '" + beanName + "' with an equivalent definition: replacing [" + existingDefinition + "] with [" + beanDefinition + "]" ); } this .beanDefinitionMap.put(beanName, beanDefinition); } else { if (this .hasBeanCreationStarted()) { synchronized (this .beanDefinitionMap) { this .beanDefinitionMap.put(beanName, beanDefinition); List<String> updatedDefinitions = new ArrayList(this .beanDefinitionNames.size() + 1 ); updatedDefinitions.addAll(this .beanDefinitionNames); updatedDefinitions.add(beanName); this .beanDefinitionNames = updatedDefinitions; if (this .manualSingletonNames.contains(beanName)) { Set<String> updatedSingletons = new LinkedHashSet(this .manualSingletonNames); updatedSingletons.remove(beanName); this .manualSingletonNames = updatedSingletons; } } } else { this .beanDefinitionMap.put(beanName, beanDefinition); this .beanDefinitionNames.add(beanName); this .manualSingletonNames.remove(beanName); } this .frozenBeanDefinitionNames = null ; } if (existingDefinition != null || this .containsSingleton(beanName)) { this .resetBeanDefinition(beanName); } }
Spring BeanDefinition 合并阶段
BeanDefinition 合并
父子 BeanDefinition 合并
当前 BeanFactory 查找
层次性 BeanFactory 查找
1 2 3 4 5 6 7 8 9 public abstract class AbstractBeanFactory extends FactoryBeanRegistrySupport implements ConfigurableBeanFactory @Override public BeanDefinition getMergedBeanDefinition (String name) throws BeansException String beanName = this .transformedBeanName(name); return (BeanDefinition)(!this .containsBeanDefinition(beanName) && this .getParentBeanFactory() instanceof ConfigurableBeanFactory ? ((ConfigurableBeanFactory)this .getParentBeanFactory()).getMergedBeanDefinition(beanName) : this .getMergedLocalBeanDefinition(beanName)); } }
一般的 BeanDefinition 是从 GenericBeanDefinition 转换成 RootBeanDefinition。子的 BeanDeifinition 去合并(merge)父的 BeanDefinition 相关配置。
Spring Bean Class 加载阶段 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 protected <T> T doGetBean (String name, @Nullable Class<T> requiredType, @Nullable Object[] args, boolean typeCheckOnly) throws BeansException { String beanName = this .transformedBeanName(name); Object sharedInstance = this .getSingleton(beanName); Object bean; if (sharedInstance != null && args == null ) { if (this .logger.isTraceEnabled()) { if (this .isSingletonCurrentlyInCreation(beanName)) { this .logger.trace("Returning eagerly cached instance of singleton bean '" + beanName + "' that is not fully initialized yet - a consequence of a circular reference" ); } else { this .logger.trace("Returning cached instance of singleton bean '" + beanName + "'" ); } } bean = this .getObjectForBeanInstance(sharedInstance, name, beanName, (RootBeanDefinition)null ); } else { if (this .isPrototypeCurrentlyInCreation(beanName)) { throw new BeanCurrentlyInCreationException(beanName); } BeanFactory parentBeanFactory = this .getParentBeanFactory(); if (parentBeanFactory != null && !this .containsBeanDefinition(beanName)) { String nameToLookup = this .originalBeanName(name); if (parentBeanFactory instanceof AbstractBeanFactory) { return ((AbstractBeanFactory)parentBeanFactory).doGetBean(nameToLookup, requiredType, args, typeCheckOnly); } if (args != null ) { return parentBeanFactory.getBean(nameToLookup, args); } if (requiredType != null ) { return parentBeanFactory.getBean(nameToLookup, requiredType); } return parentBeanFactory.getBean(nameToLookup); } if (!typeCheckOnly) { this .markBeanAsCreated(beanName); } try { RootBeanDefinition mbd = this .getMergedLocalBeanDefinition(beanName); this .checkMergedBeanDefinition(mbd, beanName, args); String[] dependsOn = mbd.getDependsOn(); String[] var11; if (dependsOn != null ) { var11 = dependsOn; int var12 = dependsOn.length; for (int var13 = 0 ; var13 < var12; ++var13) { String dep = var11[var13]; if (this .isDependent(beanName, dep)) { throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Circular depends-on relationship between '" + beanName + "' and '" + dep + "'" ); } this .registerDependentBean(dep, beanName); try { this .getBean(dep); } catch (NoSuchBeanDefinitionException var24) { throw new BeanCreationException(mbd.getResourceDescription(), beanName, "'" + beanName + "' depends on missing bean '" + dep + "'" , var24); } } } if (mbd.isSingleton()) { sharedInstance = this .getSingleton(beanName, () -> { try { return this .createBean(beanName, mbd, args); } catch (BeansException var5) { this .destroySingleton(beanName); throw var5; } }); bean = this .getObjectForBeanInstance(sharedInstance, name, beanName, mbd); } else if (mbd.isPrototype()) { var11 = null ; Object prototypeInstance; try { this .beforePrototypeCreation(beanName); prototypeInstance = this .createBean(beanName, mbd, args); } finally { this .afterPrototypeCreation(beanName); } bean = this .getObjectForBeanInstance(prototypeInstance, name, beanName, mbd); } else { String scopeName = mbd.getScope(); Scope scope = (Scope)this .scopes.get(scopeName); if (scope == null ) { throw new IllegalStateException("No Scope registered for scope name '" + scopeName + "'" ); } try { Object scopedInstance = scope.get(beanName, () -> { this .beforePrototypeCreation(beanName); Object var4; try { var4 = this .createBean(beanName, mbd, args); } finally { this .afterPrototypeCreation(beanName); } return var4; }); bean = this .getObjectForBeanInstance(scopedInstance, name, beanName, mbd); } catch (IllegalStateException var23) { throw new BeanCreationException(beanName, "Scope '" + scopeName + "' is not active for the current thread; consider defining a scoped proxy for this bean if you intend to refer to it from a singleton" , var23); } } } catch (BeansException var26) { this .cleanupAfterBeanCreationFailure(beanName); throw var26; } } if (requiredType != null && !requiredType.isInstance(bean)) { try { T convertedBean = this .getTypeConverter().convertIfNecessary(bean, requiredType); if (convertedBean == null ) { throw new BeanNotOfRequiredTypeException(name, requiredType, bean.getClass()); } else { return convertedBean; } } catch (TypeMismatchException var25) { if (this .logger.isTraceEnabled()) { this .logger.trace("Failed to convert bean '" + name + "' to required type '" + ClassUtils.getQualifiedName(requiredType) + "'" , var25); } throw new BeanNotOfRequiredTypeException(name, requiredType, bean.getClass()); } } else { return bean; } } public Object getSingleton (String beanName, ObjectFactory<?> singletonFactory) Assert.notNull(beanName, "Bean name must not be null" ); synchronized (this .singletonObjects) { Object singletonObject = this .singletonObjects.get(beanName); if (singletonObject == null ) { if (this .singletonsCurrentlyInDestruction) { throw new BeanCreationNotAllowedException(beanName, "Singleton bean creation not allowed while singletons of this factory are in destruction (Do not request a bean from a BeanFactory in a destroy method implementation!)" ); } if (this .logger.isDebugEnabled()) { this .logger.debug("Creating shared instance of singleton bean '" + beanName + "'" ); } this .beforeSingletonCreation(beanName); boolean newSingleton = false ; boolean recordSuppressedExceptions = this .suppressedExceptions == null ; if (recordSuppressedExceptions) { this .suppressedExceptions = new LinkedHashSet(); } try { singletonObject = singletonFactory.getObject(); newSingleton = true ; } catch (IllegalStateException var16) { singletonObject = this .singletonObjects.get(beanName); if (singletonObject == null ) { throw var16; } } catch (BeanCreationException var17) { BeanCreationException ex = var17; if (recordSuppressedExceptions) { Iterator var8 = this .suppressedExceptions.iterator(); while (var8.hasNext()) { Exception suppressedException = (Exception)var8.next(); ex.addRelatedCause(suppressedException); } } throw ex; } finally { if (recordSuppressedExceptions) { this .suppressedExceptions = null ; } this .afterSingletonCreation(beanName); } if (newSingleton) { this .addSingleton(beanName, singletonObject); } } return singletonObject; } } protected Object createBean (String beanName, RootBeanDefinition mbd, @Nullable Object[] args) throws BeanCreationException if (this .logger.isTraceEnabled()) { this .logger.trace("Creating instance of bean '" + beanName + "'" ); } RootBeanDefinition mbdToUse = mbd; Class<?> resolvedClass = this .resolveBeanClass(mbd, beanName, new Class[0 ]); if (resolvedClass != null && !mbd.hasBeanClass() && mbd.getBeanClassName() != null ) { mbdToUse = new RootBeanDefinition(mbd); mbdToUse.setBeanClass(resolvedClass); } try { mbdToUse.prepareMethodOverrides(); } catch (BeanDefinitionValidationException var9) { throw new BeanDefinitionStoreException(mbdToUse.getResourceDescription(), beanName, "Validation of method overrides failed" , var9); } Object beanInstance; try { beanInstance = this .resolveBeforeInstantiation(beanName, mbdToUse); if (beanInstance != null ) { return beanInstance; } } catch (Throwable var10) { throw new BeanCreationException(mbdToUse.getResourceDescription(), beanName, "BeanPostProcessor before instantiation of bean failed" , var10); } try { beanInstance = this .doCreateBean(beanName, mbdToUse, args); if (this .logger.isTraceEnabled()) { this .logger.trace("Finished creating instance of bean '" + beanName + "'" ); } return beanInstance; } catch (ImplicitlyAppearedSingletonException | BeanCreationException var7) { throw var7; } catch (Throwable var8) { throw new BeanCreationException(mbdToUse.getResourceDescription(), beanName, "Unexpected exception during bean creation" , var8); } } @Nullable protected Class<?> resolveBeanClass(RootBeanDefinition mbd, String beanName, Class<?>... typesToMatch) throws CannotLoadBeanClassException { try { if (mbd.hasBeanClass()) { return mbd.getBeanClass(); } else { return System.getSecurityManager() != null ? (Class)AccessController.doPrivileged(() -> { return this .doResolveBeanClass(mbd, typesToMatch); }, this .getAccessControlContext()) : this .doResolveBeanClass(mbd, typesToMatch); } } catch (PrivilegedActionException var6) { ClassNotFoundException ex = (ClassNotFoundException)var6.getException(); throw new CannotLoadBeanClassException(mbd.getResourceDescription(), beanName, mbd.getBeanClassName(), ex); } catch (ClassNotFoundException var7) { throw new CannotLoadBeanClassException(mbd.getResourceDescription(), beanName, mbd.getBeanClassName(), var7); } catch (LinkageError var8) { throw new CannotLoadBeanClassException(mbd.getResourceDescription(), beanName, mbd.getBeanClassName(), var8); } } private Class<?> doResolveBeanClass(RootBeanDefinition mbd, Class<?>... typesToMatch) throws ClassNotFoundException { ClassLoader beanClassLoader = this .getBeanClassLoader(); ClassLoader dynamicLoader = beanClassLoader; boolean freshResolve = false ; if (!ObjectUtils.isEmpty(typesToMatch)) { ClassLoader tempClassLoader = this .getTempClassLoader(); if (tempClassLoader != null ) { dynamicLoader = tempClassLoader; freshResolve = true ; if (tempClassLoader instanceof DecoratingClassLoader) { DecoratingClassLoader dcl = (DecoratingClassLoader)tempClassLoader; Class[] var8 = typesToMatch; int var9 = typesToMatch.length; for (int var10 = 0 ; var10 < var9; ++var10) { Class<?> typeToMatch = var8[var10]; dcl.excludeClass(typeToMatch.getName()); } } } } String className = mbd.getBeanClassName(); if (className != null ) { Object evaluated = this .evaluateBeanDefinitionString(className, mbd); if (!className.equals(evaluated)) { if (evaluated instanceof Class) { return (Class)evaluated; } if (!(evaluated instanceof String)) { throw new IllegalStateException("Invalid class name expression result: " + evaluated); } className = (String)evaluated; freshResolve = true ; } if (freshResolve) { if (dynamicLoader != null ) { try { return dynamicLoader.loadClass(className); } catch (ClassNotFoundException var12) { if (this .logger.isTraceEnabled()) { this .logger.trace("Could not load class [" + className + "] from " + dynamicLoader + ": " + var12); } } } return ClassUtils.forName(className, dynamicLoader); } } return mbd.resolveBeanClass(beanClassLoader); } @Nullable public Class<?> resolveBeanClass(@Nullable ClassLoader classLoader) throws ClassNotFoundException { String className = this .getBeanClassName(); if (className == null ) { return null ; } else { Class<?> resolvedClass = ClassUtils.forName(className, classLoader); this .beanClass = resolvedClass; return resolvedClass; } }
至此 BeanDefinition 变成 Class 的操作已经结束。一般情况下,就是利用 加载 BeanFactory 的ClassLoader来加载,只是多了个 Java 安全的校验加载。
Spring Bean 实例化前阶段 主要是下面这个接口,在Spring 5前面有个Adpter类,就是和 WebMvcConfigurerAdapter 一样,为了适配之后的类。继承这个接口,实现 postProcessBeforeInstantiation 方法,就可以对 Bean 实例化前进行操作。增强事务功能就是对这个方法进行了改造。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 public interface InstantiationAwareBeanPostProcessor extends BeanPostProcessor @Nullable default Object postProcessBeforeInstantiation (Class<?> beanClass, String beanName) throws BeansException return null ; } default boolean postProcessAfterInstantiation (Object bean, String beanName) throws BeansException return true ; } @Nullable default PropertyValues postProcessProperties (PropertyValues pvs, Object bean, String beanName) throws BeansException return null ; } @Deprecated @Nullable default PropertyValues postProcessPropertyValues (PropertyValues pvs, PropertyDescriptor[] pds, Object bean, String beanName) throws BeansException return pvs; } } protected Object createBean (String beanName, RootBeanDefinition mbd, @Nullable Object[] args) throws BeanCreationException if (this .logger.isTraceEnabled()) { this .logger.trace("Creating instance of bean '" + beanName + "'" ); } RootBeanDefinition mbdToUse = mbd; Class<?> resolvedClass = this .resolveBeanClass(mbd, beanName, new Class[0 ]); if (resolvedClass != null && !mbd.hasBeanClass() && mbd.getBeanClassName() != null ) { mbdToUse = new RootBeanDefinition(mbd); mbdToUse.setBeanClass(resolvedClass); } try { mbdToUse.prepareMethodOverrides(); } catch (BeanDefinitionValidationException var9) { throw new BeanDefinitionStoreException(mbdToUse.getResourceDescription(), beanName, "Validation of method overrides failed" , var9); } Object beanInstance; try { beanInstance = this .resolveBeforeInstantiation(beanName, mbdToUse); if (beanInstance != null ) { return beanInstance; } } catch (Throwable var10) { throw new BeanCreationException(mbdToUse.getResourceDescription(), beanName, "BeanPostProcessor before instantiation of bean failed" , var10); } try { beanInstance = this .doCreateBean(beanName, mbdToUse, args); if (this .logger.isTraceEnabled()) { this .logger.trace("Finished creating instance of bean '" + beanName + "'" ); } return beanInstance; } catch (ImplicitlyAppearedSingletonException | BeanCreationException var7) { throw var7; } catch (Throwable var8) { throw new BeanCreationException(mbdToUse.getResourceDescription(), beanName, "Unexpected exception during bean creation" , var8); } } @Nullable protected Object resolveBeforeInstantiation (String beanName, RootBeanDefinition mbd) Object bean = null ; if (!Boolean.FALSE.equals(mbd.beforeInstantiationResolved)) { if (!mbd.isSynthetic() && this .hasInstantiationAwareBeanPostProcessors()) { Class<?> targetType = this .determineTargetType(beanName, mbd); if (targetType != null ) { bean = this .applyBeanPostProcessorsBeforeInstantiation(targetType, beanName); if (bean != null ) { bean = this .applyBeanPostProcessorsAfterInitialization(bean, beanName); } } } mbd.beforeInstantiationResolved = bean != null ; } return bean; } protected Object doCreateBean (String beanName, RootBeanDefinition mbd, @Nullable Object[] args) throws BeanCreationException BeanWrapper instanceWrapper = null ; if (mbd.isSingleton()) { instanceWrapper = (BeanWrapper)this .factoryBeanInstanceCache.remove(beanName); } if (instanceWrapper == null ) { instanceWrapper = this .createBeanInstance(beanName, mbd, args); } Object bean = instanceWrapper.getWrappedInstance(); Class<?> beanType = instanceWrapper.getWrappedClass(); if (beanType != NullBean.class ) { mbd.resolvedTargetType = beanType; } synchronized (mbd.postProcessingLock) { if (!mbd.postProcessed) { try { this .applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName); } catch (Throwable var17) { throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Post-processing of merged bean definition failed" , var17); } mbd.postProcessed = true ; } } boolean earlySingletonExposure = mbd.isSingleton() && this .allowCircularReferences && this .isSingletonCurrentlyInCreation(beanName); if (earlySingletonExposure) { if (this .logger.isTraceEnabled()) { this .logger.trace("Eagerly caching bean '" + beanName + "' to allow for resolving potential circular references" ); } this .addSingletonFactory(beanName, () -> { return this .getEarlyBeanReference(beanName, mbd, bean); }); } Object exposedObject = bean; try { this .populateBean(beanName, mbd, instanceWrapper); exposedObject = this .initializeBean(beanName, exposedObject, mbd); } catch (Throwable var18) { if (var18 instanceof BeanCreationException && beanName.equals(((BeanCreationException)var18).getBeanName())) { throw (BeanCreationException)var18; } throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Initialization of bean failed" , var18); } if (earlySingletonExposure) { Object earlySingletonReference = this .getSingleton(beanName, false ); if (earlySingletonReference != null ) { if (exposedObject == bean) { exposedObject = earlySingletonReference; } else if (!this .allowRawInjectionDespiteWrapping && this .hasDependentBean(beanName)) { String[] dependentBeans = this .getDependentBeans(beanName); Set<String> actualDependentBeans = new LinkedHashSet(dependentBeans.length); String[] var12 = dependentBeans; int var13 = dependentBeans.length; for (int var14 = 0 ; var14 < var13; ++var14) { String dependentBean = var12[var14]; if (!this .removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) { actualDependentBeans.add(dependentBean); } } if (!actualDependentBeans.isEmpty()) { throw new BeanCurrentlyInCreationException(beanName, "Bean with name '" + beanName + "' has been injected into other beans [" + StringUtils.collectionToCommaDelimitedString(actualDependentBeans) + "] in its raw version as part of a circular reference, but has eventually been wrapped. This means that said other beans do not use the final version of the bean. This is often the result of over-eager type matching - consider using 'getBeanNamesOfType' with the 'allowEagerInit' flag turned off, for example." ); } } } } try { this .registerDisposableBeanIfNecessary(beanName, bean, mbd); return exposedObject; } catch (BeanDefinitionValidationException var16) { throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Invalid destruction signature" , var16); } } protected void populateBean (String beanName, RootBeanDefinition mbd, @Nullable BeanWrapper bw) if (bw == null ) { if (mbd.hasPropertyValues()) { throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Cannot apply property values to null instance" ); } } else { boolean continueWithPropertyPopulation = true ; if (!mbd.isSynthetic() && this .hasInstantiationAwareBeanPostProcessors()) { Iterator var5 = this .getBeanPostProcessors().iterator(); while (var5.hasNext()) { BeanPostProcessor bp = (BeanPostProcessor)var5.next(); if (bp instanceof InstantiationAwareBeanPostProcessor) { InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor)bp; if (!ibp.postProcessAfterInstantiation(bw.getWrappedInstance(), beanName)) { continueWithPropertyPopulation = false ; break ; } } } } if (continueWithPropertyPopulation) { PropertyValues pvs = mbd.hasPropertyValues() ? mbd.getPropertyValues() : null ; if (mbd.getResolvedAutowireMode() == 1 || mbd.getResolvedAutowireMode() == 2 ) { MutablePropertyValues newPvs = new MutablePropertyValues((PropertyValues)pvs); if (mbd.getResolvedAutowireMode() == 1 ) { this .autowireByName(beanName, mbd, bw, newPvs); } if (mbd.getResolvedAutowireMode() == 2 ) { this .autowireByType(beanName, mbd, bw, newPvs); } pvs = newPvs; } boolean hasInstAwareBpps = this .hasInstantiationAwareBeanPostProcessors(); boolean needsDepCheck = mbd.getDependencyCheck() != 0 ; PropertyDescriptor[] filteredPds = null ; if (hasInstAwareBpps) { if (pvs == null ) { pvs = mbd.getPropertyValues(); } Iterator var9 = this .getBeanPostProcessors().iterator(); while (var9.hasNext()) { BeanPostProcessor bp = (BeanPostProcessor)var9.next(); if (bp instanceof InstantiationAwareBeanPostProcessor) { InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor)bp; PropertyValues pvsToUse = ibp.postProcessProperties((PropertyValues)pvs, bw.getWrappedInstance(), beanName); if (pvsToUse == null ) { if (filteredPds == null ) { filteredPds = this .filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching); } pvsToUse = ibp.postProcessPropertyValues((PropertyValues)pvs, filteredPds, bw.getWrappedInstance(), beanName); if (pvsToUse == null ) { return ; } } pvs = pvsToUse; } } } if (needsDepCheck) { if (filteredPds == null ) { filteredPds = this .filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching); } this .checkDependencies(beanName, mbd, filteredPds, (PropertyValues)pvs); } if (pvs != null ) { this .applyPropertyValues(beanName, mbd, bw, (PropertyValues)pvs); } } } } protected Object initializeBean (String beanName, Object bean, @Nullable RootBeanDefinition mbd) if (System.getSecurityManager() != null ) { AccessController.doPrivileged(() -> { this .invokeAwareMethods(beanName, bean); return null ; }, this .getAccessControlContext()); } else { this .invokeAwareMethods(beanName, bean); } Object wrappedBean = bean; if (mbd == null || !mbd.isSynthetic()) { wrappedBean = this .applyBeanPostProcessorsBeforeInitialization(bean, beanName); } try { this .invokeInitMethods(beanName, wrappedBean, mbd); } catch (Throwable var6) { throw new BeanCreationException(mbd != null ? mbd.getResourceDescription() : null , beanName, "Invocation of init method failed" , var6); } if (mbd == null || !mbd.isSynthetic()) { wrappedBean = this .applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName); } return wrappedBean; } private void invokeAwareMethods (String beanName, Object bean) if (bean instanceof Aware) { if (bean instanceof BeanNameAware) { ((BeanNameAware)bean).setBeanName(beanName); } if (bean instanceof BeanClassLoaderAware) { ClassLoader bcl = this .getBeanClassLoader(); if (bcl != null ) { ((BeanClassLoaderAware)bean).setBeanClassLoader(bcl); } } if (bean instanceof BeanFactoryAware) { ((BeanFactoryAware)bean).setBeanFactory(this ); } } }
Spring Bean 实例化阶段
传统实例化方式
实例化策略 - InstantiationStrategy
构造器依赖注入(这里的一个方法有几百行代码,去验证,加载,如果参数比较多,不建议构造器注入)
实例化就是上面的 doCreateBean 方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 protected Object doCreateBean (String beanName, RootBeanDefinition mbd, @Nullable Object[] args) throws BeanCreationException BeanWrapper instanceWrapper = null ; if (mbd.isSingleton()) { instanceWrapper = (BeanWrapper)this .factoryBeanInstanceCache.remove(beanName); } if (instanceWrapper == null ) { instanceWrapper = this .createBeanInstance(beanName, mbd, args); } Object bean = instanceWrapper.getWrappedInstance(); Class<?> beanType = instanceWrapper.getWrappedClass(); if (beanType != NullBean.class ) { mbd.resolvedTargetType = beanType; } synchronized (mbd.postProcessingLock) { if (!mbd.postProcessed) { try { this .applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName); } catch (Throwable var17) { throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Post-processing of merged bean definition failed" , var17); } mbd.postProcessed = true ; } } boolean earlySingletonExposure = mbd.isSingleton() && this .allowCircularReferences && this .isSingletonCurrentlyInCreation(beanName); if (earlySingletonExposure) { if (this .logger.isTraceEnabled()) { this .logger.trace("Eagerly caching bean '" + beanName + "' to allow for resolving potential circular references" ); } this .addSingletonFactory(beanName, () -> { return this .getEarlyBeanReference(beanName, mbd, bean); }); } Object exposedObject = bean; try { this .populateBean(beanName, mbd, instanceWrapper); exposedObject = this .initializeBean(beanName, exposedObject, mbd); } catch (Throwable var18) { if (var18 instanceof BeanCreationException && beanName.equals(((BeanCreationException)var18).getBeanName())) { throw (BeanCreationException)var18; } throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Initialization of bean failed" , var18); } if (earlySingletonExposure) { Object earlySingletonReference = this .getSingleton(beanName, false ); if (earlySingletonReference != null ) { if (exposedObject == bean) { exposedObject = earlySingletonReference; } else if (!this .allowRawInjectionDespiteWrapping && this .hasDependentBean(beanName)) { String[] dependentBeans = this .getDependentBeans(beanName); Set<String> actualDependentBeans = new LinkedHashSet(dependentBeans.length); String[] var12 = dependentBeans; int var13 = dependentBeans.length; for (int var14 = 0 ; var14 < var13; ++var14) { String dependentBean = var12[var14]; if (!this .removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) { actualDependentBeans.add(dependentBean); } } if (!actualDependentBeans.isEmpty()) { throw new BeanCurrentlyInCreationException(beanName, "Bean with name '" + beanName + "' has been injected into other beans [" + StringUtils.collectionToCommaDelimitedString(actualDependentBeans) + "] in its raw version as part of a circular reference, but has eventually been wrapped. This means that said other beans do not use the final version of the bean. This is often the result of over-eager type matching - consider using 'getBeanNamesOfType' with the 'allowEagerInit' flag turned off, for example." ); } } } } try { this .registerDisposableBeanIfNecessary(beanName, bean, mbd); return exposedObject; } catch (BeanDefinitionValidationException var16) { throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Invalid destruction signature" , var16); } } protected BeanWrapper createBeanInstance (String beanName, RootBeanDefinition mbd, @Nullable Object[] args) Class<?> beanClass = this .resolveBeanClass(mbd, beanName, new Class[0 ]); if (beanClass != null && !Modifier.isPublic(beanClass.getModifiers()) && !mbd.isNonPublicAccessAllowed()) { throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Bean class isn't public, and non-public access not allowed: " + beanClass.getName()); } else { Supplier<?> instanceSupplier = mbd.getInstanceSupplier(); if (instanceSupplier != null ) { return this .obtainFromSupplier(instanceSupplier, beanName); } else if (mbd.getFactoryMethodName() != null ) { return this .instantiateUsingFactoryMethod(beanName, mbd, args); } else { boolean resolved = false ; boolean autowireNecessary = false ; if (args == null ) { synchronized (mbd.constructorArgumentLock) { if (mbd.resolvedConstructorOrFactoryMethod != null ) { resolved = true ; autowireNecessary = mbd.constructorArgumentsResolved; } } } if (resolved) { return autowireNecessary ? this .autowireConstructor(beanName, mbd, (Constructor[])null , (Object[])null ) : this .instantiateBean(beanName, mbd); } else { Constructor<?>[] ctors = this .determineConstructorsFromBeanPostProcessors(beanClass, beanName); if (ctors == null && mbd.getResolvedAutowireMode() != 3 && !mbd.hasConstructorArgumentValues() && ObjectUtils.isEmpty(args)) { ctors = mbd.getPreferredConstructors(); return ctors != null ? this .autowireConstructor(beanName, mbd, ctors, (Object[])null ) : this .instantiateBean(beanName, mbd); } else { return this .autowireConstructor(beanName, mbd, ctors, args); } } } } } protected BeanWrapper instantiateBean (String beanName, RootBeanDefinition mbd) try { Object beanInstance; if (System.getSecurityManager() != null ) { beanInstance = AccessController.doPrivileged(() -> { return thisx.getInstantiationStrategy().instantiate(mbd, beanName, this ); }, this .getAccessControlContext()); } else { beanInstance = this .getInstantiationStrategy().instantiate(mbd, beanName, this ); } BeanWrapper bw = new BeanWrapperImpl(beanInstance); this .initBeanWrapper(bw); return bw; } catch (Throwable var6) { throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Instantiation of bean failed" , var6); } } public AbstractAutowireCapableBeanFactory () this .instantiationStrategy = new CglibSubclassingInstantiationStrategy(); this .parameterNameDiscoverer = new DefaultParameterNameDiscoverer(); this .allowCircularReferences = true ; this .allowRawInjectionDespiteWrapping = false ; this .ignoredDependencyTypes = new HashSet(); this .ignoredDependencyInterfaces = new HashSet(); this .currentlyCreatedBean = new NamedThreadLocal("Currently created bean" ); this .factoryBeanInstanceCache = new ConcurrentHashMap(); this .factoryMethodCandidateCache = new ConcurrentHashMap(); this .filteredPropertyDescriptorsCache = new ConcurrentHashMap(); this .ignoreDependencyInterface(BeanNameAware.class ) ; this .ignoreDependencyInterface(BeanFactoryAware.class ) ; this .ignoreDependencyInterface(BeanClassLoaderAware.class ) ; } public Object (RootBeanDefinition bd, @Nullable String beanName, BeanFactory owner) if (!bd.hasMethodOverrides()) { Constructor constructorToUse; synchronized (bd.constructorArgumentLock) { constructorToUse = (Constructor)bd.resolvedConstructorOrFactoryMethod; if (constructorToUse == null ) { Class<?> clazz = bd.getBeanClass(); if (clazz.isInterface()) { throw new BeanInstantiationException(clazz, "Specified class is an interface" ); } try { if (System.getSecurityManager() != null ) { clazz.getClass(); constructorToUse = (Constructor)AccessController.doPrivileged(() -> { return clazz.getDeclaredConstructor(); }); } else { constructorToUse = clazz.getDeclaredConstructor(); } bd.resolvedConstructorOrFactoryMethod = constructorToUse; } catch (Throwable var9) { throw new BeanInstantiationException(clazz, "No default constructor found" , var9); } } } return BeanUtils.instantiateClass(constructorToUse, new Object[0 ]); } else { return this .instantiateWithMethodInjection(bd, beanName, owner); } } @Nullable protected Constructor<?>[] determineConstructorsFromBeanPostProcessors(@Nullable Class<?> beanClass, String beanName) throws BeansException { if (beanClass != null && this .hasInstantiationAwareBeanPostProcessors()) { Iterator var3 = this .getBeanPostProcessors().iterator(); while (var3.hasNext()) { BeanPostProcessor bp = (BeanPostProcessor)var3.next(); if (bp instanceof SmartInstantiationAwareBeanPostProcessor) { SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor)bp; Constructor<?>[] ctors = ibp.determineCandidateConstructors(beanClass, beanName); if (ctors != null ) { return ctors; } } } } return null ; }
构造器注入,是按照类型注入。也可以通过 @Qualifier指定
Spring Bean 实例化后阶段 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 protected void populateBean (String beanName, RootBeanDefinition mbd, @Nullable BeanWrapper bw) if (bw == null ) { if (mbd.hasPropertyValues()) { throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Cannot apply property values to null instance" ); } } else { boolean continueWithPropertyPopulation = true ; if (!mbd.isSynthetic() && this .hasInstantiationAwareBeanPostProcessors()) { Iterator var5 = this .getBeanPostProcessors().iterator(); while (var5.hasNext()) { BeanPostProcessor bp = (BeanPostProcessor)var5.next(); if (bp instanceof InstantiationAwareBeanPostProcessor) { InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor)bp; if (!ibp.postProcessAfterInstantiation(bw.getWrappedInstance(), beanName)) { continueWithPropertyPopulation = false ; break ; } } } } if (continueWithPropertyPopulation) { PropertyValues pvs = mbd.hasPropertyValues() ? mbd.getPropertyValues() : null ; if (mbd.getResolvedAutowireMode() == 1 || mbd.getResolvedAutowireMode() == 2 ) { MutablePropertyValues newPvs = new MutablePropertyValues((PropertyValues)pvs); if (mbd.getResolvedAutowireMode() == 1 ) { this .autowireByName(beanName, mbd, bw, newPvs); } if (mbd.getResolvedAutowireMode() == 2 ) { this .autowireByType(beanName, mbd, bw, newPvs); } pvs = newPvs; } boolean hasInstAwareBpps = this .hasInstantiationAwareBeanPostProcessors(); boolean needsDepCheck = mbd.getDependencyCheck() != 0 ; PropertyDescriptor[] filteredPds = null ; if (hasInstAwareBpps) { if (pvs == null ) { pvs = mbd.getPropertyValues(); } Iterator var9 = this .getBeanPostProcessors().iterator(); while (var9.hasNext()) { BeanPostProcessor bp = (BeanPostProcessor)var9.next(); if (bp instanceof InstantiationAwareBeanPostProcessor) { InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor)bp; PropertyValues pvsToUse = ibp.postProcessProperties((PropertyValues)pvs, bw.getWrappedInstance(), beanName); if (pvsToUse == null ) { if (filteredPds == null ) { filteredPds = this .filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching); } pvsToUse = ibp.postProcessPropertyValues((PropertyValues)pvs, filteredPds, bw.getWrappedInstance(), beanName); if (pvsToUse == null ) { return ; } } pvs = pvsToUse; } } } if (needsDepCheck) { if (filteredPds == null ) { filteredPds = this .filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching); } this .checkDependencies(beanName, mbd, filteredPds, (PropertyValues)pvs); } if (pvs != null ) { this .applyPropertyValues(beanName, mbd, bw, (PropertyValues)pvs); } } } } @Nullable protected Object resolveBeforeInstantiation (String beanName, RootBeanDefinition mbd) Object bean = null ; if (!Boolean.FALSE.equals(mbd.beforeInstantiationResolved)) { if (!mbd.isSynthetic() && this .hasInstantiationAwareBeanPostProcessors()) { Class<?> targetType = this .determineTargetType(beanName, mbd); if (targetType != null ) { bean = this .applyBeanPostProcessorsBeforeInstantiation(targetType, beanName); if (bean != null ) { bean = this .applyBeanPostProcessorsAfterInitialization(bean, beanName); } } } mbd.beforeInstantiationResolved = bean != null ; } return bean; } protected Object createBean (String beanName, RootBeanDefinition mbd, @Nullable Object[] args) throws BeanCreationException if (this .logger.isTraceEnabled()) { this .logger.trace("Creating instance of bean '" + beanName + "'" ); } RootBeanDefinition mbdToUse = mbd; Class<?> resolvedClass = this .resolveBeanClass(mbd, beanName, new Class[0 ]); if (resolvedClass != null && !mbd.hasBeanClass() && mbd.getBeanClassName() != null ) { mbdToUse = new RootBeanDefinition(mbd); mbdToUse.setBeanClass(resolvedClass); } try { mbdToUse.prepareMethodOverrides(); } catch (BeanDefinitionValidationException var9) { throw new BeanDefinitionStoreException(mbdToUse.getResourceDescription(), beanName, "Validation of method overrides failed" , var9); } Object beanInstance; try { beanInstance = this .resolveBeforeInstantiation(beanName, mbdToUse); if (beanInstance != null ) { return beanInstance; } } catch (Throwable var10) { throw new BeanCreationException(mbdToUse.getResourceDescription(), beanName, "BeanPostProcessor before instantiation of bean failed" , var10); } try { beanInstance = this .doCreateBean(beanName, mbdToUse, args); if (this .logger.isTraceEnabled()) { this .logger.trace("Finished creating instance of bean '" + beanName + "'" ); } return beanInstance; } catch (ImplicitlyAppearedSingletonException | BeanCreationException var7) { throw var7; } catch (Throwable var8) { throw new BeanCreationException(mbdToUse.getResourceDescription(), beanName, "Unexpected exception during bean creation" , var8); } } @Nullable protected Object applyBeanPostProcessorsBeforeInstantiation (Class<?> beanClass, String beanName) Iterator var3 = this .getBeanPostProcessors().iterator(); while (var3.hasNext()) { BeanPostProcessor bp = (BeanPostProcessor)var3.next(); if (bp instanceof InstantiationAwareBeanPostProcessor) { InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor)bp; Object result = ibp.postProcessBeforeInstantiation(beanClass, beanName); if (result != null ) { return result; } } } return null ; } public Object applyBeanPostProcessorsAfterInitialization (Object existingBean, String beanName) throws BeansException Object result = existingBean; Object current; for (Iterator var4 = this .getBeanPostProcessors().iterator(); var4.hasNext(); result = current) { BeanPostProcessor processor = (BeanPostProcessor)var4.next(); current = processor.postProcessAfterInitialization(result, beanName); if (current == null ) { return result; } } return result; }
也就是为保证 postProcessAfterInitialization 方法一定执行,其实有两处互斥的地方调用了该方法。
Spring Bean 属性赋值前阶段 populateBean 就是属性赋值阶段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 protected void populateBean (String beanName, RootBeanDefinition mbd, @Nullable BeanWrapper bw) if (bw == null ) { if (mbd.hasPropertyValues()) { throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Cannot apply property values to null instance" ); } } else { boolean continueWithPropertyPopulation = true ; if (!mbd.isSynthetic() && this .hasInstantiationAwareBeanPostProcessors()) { Iterator var5 = this .getBeanPostProcessors().iterator(); while (var5.hasNext()) { BeanPostProcessor bp = (BeanPostProcessor)var5.next(); if (bp instanceof InstantiationAwareBeanPostProcessor) { InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor)bp; if (!ibp.postProcessAfterInstantiation(bw.getWrappedInstance(), beanName)) { continueWithPropertyPopulation = false ; break ; } } } } if (continueWithPropertyPopulation) { PropertyValues pvs = mbd.hasPropertyValues() ? mbd.getPropertyValues() : null ; if (mbd.getResolvedAutowireMode() == 1 || mbd.getResolvedAutowireMode() == 2 ) { MutablePropertyValues newPvs = new MutablePropertyValues((PropertyValues)pvs); if (mbd.getResolvedAutowireMode() == 1 ) { this .autowireByName(beanName, mbd, bw, newPvs); } if (mbd.getResolvedAutowireMode() == 2 ) { this .autowireByType(beanName, mbd, bw, newPvs); } pvs = newPvs; } boolean hasInstAwareBpps = this .hasInstantiationAwareBeanPostProcessors(); boolean needsDepCheck = mbd.getDependencyCheck() != 0 ; PropertyDescriptor[] filteredPds = null ; if (hasInstAwareBpps) { if (pvs == null ) { pvs = mbd.getPropertyValues(); } Iterator var9 = this .getBeanPostProcessors().iterator(); while (var9.hasNext()) { BeanPostProcessor bp = (BeanPostProcessor)var9.next(); if (bp instanceof InstantiationAwareBeanPostProcessor) { InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor)bp; PropertyValues pvsToUse = ibp.postProcessProperties((PropertyValues)pvs, bw.getWrappedInstance(), beanName); if (pvsToUse == null ) { if (filteredPds == null ) { filteredPds = this .filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching); } pvsToUse = ibp.postProcessPropertyValues((PropertyValues)pvs, filteredPds, bw.getWrappedInstance(), beanName); if (pvsToUse == null ) { return ; } } pvs = pvsToUse; } } } if (needsDepCheck) { if (filteredPds == null ) { filteredPds = this .filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching); } this .checkDependencies(beanName, mbd, filteredPds, (PropertyValues)pvs); } if (pvs != null ) { this .applyPropertyValues(beanName, mbd, bw, (PropertyValues)pvs); } } } }
Spring Bean Aware 接口回调阶段 按顺序执行
BeanNameAware
BeanClassLoaderAware
BeanFactoryAware
EnvironmentAware //这个和接下来是 applicationContext 执行的
EmbeddedValueResolverAware
ResourceLoaderAware
ApplicationEventPublisherAware
MessageSourceAware
ApplicationContextAware
在执行 populateBean 方法之后,执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 private void invokeAwareMethods (String beanName, Object bean) if (bean instanceof Aware) { if (bean instanceof BeanNameAware) { ((BeanNameAware)bean).setBeanName(beanName); } if (bean instanceof BeanClassLoaderAware) { ClassLoader bcl = this .getBeanClassLoader(); if (bcl != null ) { ((BeanClassLoaderAware)bean).setBeanClassLoader(bcl); } } if (bean instanceof BeanFactoryAware) { ((BeanFactoryAware)bean).setBeanFactory(this ); } } } protected Object initializeBean (String beanName, Object bean, @Nullable RootBeanDefinition mbd) if (System.getSecurityManager() != null ) { AccessController.doPrivileged(() -> { this .invokeAwareMethods(beanName, bean); return null ; }, this .getAccessControlContext()); } else { this .invokeAwareMethods(beanName, bean); } Object wrappedBean = bean; if (mbd == null || !mbd.isSynthetic()) { wrappedBean = this .applyBeanPostProcessorsBeforeInitialization(bean, beanName); } try { this .invokeInitMethods(beanName, wrappedBean, mbd); } catch (Throwable var6) { throw new BeanCreationException(mbd != null ? mbd.getResourceDescription() : null , beanName, "Invocation of init method failed" , var6); } if (mbd == null || !mbd.isSynthetic()) { wrappedBean = this .applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName); } return wrappedBean; } protected Object doCreateBean (String beanName, RootBeanDefinition mbd, @Nullable Object[] args) throws BeanCreationException BeanWrapper instanceWrapper = null ; if (mbd.isSingleton()) { instanceWrapper = (BeanWrapper)this .factoryBeanInstanceCache.remove(beanName); } if (instanceWrapper == null ) { instanceWrapper = this .createBeanInstance(beanName, mbd, args); } Object bean = instanceWrapper.getWrappedInstance(); Class<?> beanType = instanceWrapper.getWrappedClass(); if (beanType != NullBean.class ) { mbd.resolvedTargetType = beanType; } synchronized (mbd.postProcessingLock) { if (!mbd.postProcessed) { try { this .applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName); } catch (Throwable var17) { throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Post-processing of merged bean definition failed" , var17); } mbd.postProcessed = true ; } } boolean earlySingletonExposure = mbd.isSingleton() && this .allowCircularReferences && this .isSingletonCurrentlyInCreation(beanName); if (earlySingletonExposure) { if (this .logger.isTraceEnabled()) { this .logger.trace("Eagerly caching bean '" + beanName + "' to allow for resolving potential circular references" ); } this .addSingletonFactory(beanName, () -> { return this .getEarlyBeanReference(beanName, mbd, bean); }); } Object exposedObject = bean; try { this .populateBean(beanName, mbd, instanceWrapper); exposedObject = this .initializeBean(beanName, exposedObject, mbd); } catch (Throwable var18) { if (var18 instanceof BeanCreationException && beanName.equals(((BeanCreationException)var18).getBeanName())) { throw (BeanCreationException)var18; } throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Initialization of bean failed" , var18); } if (earlySingletonExposure) { Object earlySingletonReference = this .getSingleton(beanName, false ); if (earlySingletonReference != null ) { if (exposedObject == bean) { exposedObject = earlySingletonReference; } else if (!this .allowRawInjectionDespiteWrapping && this .hasDependentBean(beanName)) { String[] dependentBeans = this .getDependentBeans(beanName); Set<String> actualDependentBeans = new LinkedHashSet(dependentBeans.length); String[] var12 = dependentBeans; int var13 = dependentBeans.length; for (int var14 = 0 ; var14 < var13; ++var14) { String dependentBean = var12[var14]; if (!this .removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) { actualDependentBeans.add(dependentBean); } } if (!actualDependentBeans.isEmpty()) { throw new BeanCurrentlyInCreationException(beanName, "Bean with name '" + beanName + "' has been injected into other beans [" + StringUtils.collectionToCommaDelimitedString(actualDependentBeans) + "] in its raw version as part of a circular reference, but has eventually been wrapped. This means that said other beans do not use the final version of the bean. This is often the result of over-eager type matching - consider using 'getBeanNamesOfType' with the 'allowEagerInit' flag turned off, for example." ); } } } } try { this .registerDisposableBeanIfNecessary(beanName, bean, mbd); return exposedObject; } catch (BeanDefinitionValidationException var16) { throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Invalid destruction signature" , var16); } } private void invokeAwareInterfaces (Object bean) if (bean instanceof Aware) { if (bean instanceof EnvironmentAware) { ((EnvironmentAware)bean).setEnvironment(this .applicationContext.getEnvironment()); } if (bean instanceof EmbeddedValueResolverAware) { ((EmbeddedValueResolverAware)bean).setEmbeddedValueResolver(this .embeddedValueResolver); } if (bean instanceof ResourceLoaderAware) { ((ResourceLoaderAware)bean).setResourceLoader(this .applicationContext); } if (bean instanceof ApplicationEventPublisherAware) { ((ApplicationEventPublisherAware)bean).setApplicationEventPublisher(this .applicationContext); } if (bean instanceof MessageSourceAware) { ((MessageSourceAware)bean).setMessageSource(this .applicationContext); } if (bean instanceof ApplicationContextAware) { ((ApplicationContextAware)bean).setApplicationContext(this .applicationContext); } } } @Nullable public Object postProcessBeforeInitialization (Object bean, String beanName) throws BeansException AccessControlContext acc = null ; if (System.getSecurityManager() != null && (bean instanceof EnvironmentAware || bean instanceof EmbeddedValueResolverAware || bean instanceof ResourceLoaderAware || bean instanceof ApplicationEventPublisherAware || bean instanceof MessageSourceAware || bean instanceof ApplicationContextAware)) { acc = this .applicationContext.getBeanFactory().getAccessControlContext(); } if (acc != null ) { AccessController.doPrivileged(() -> { this .invokeAwareInterfaces(bean); return null ; }, acc); } else { this .invokeAwareInterfaces(bean); } return bean; } protected void prepareBeanFactory (ConfigurableListableBeanFactory beanFactory) beanFactory.setBeanClassLoader(this .getClassLoader()); beanFactory.setBeanExpressionResolver(new StandardBeanExpressionResolver(beanFactory.getBeanClassLoader())); beanFactory.addPropertyEditorRegistrar(new ResourceEditorRegistrar(this , this .getEnvironment())); beanFactory.addBeanPostProcessor(new ApplicationContextAwareProcessor(this )); beanFactory.ignoreDependencyInterface(EnvironmentAware.class ) ; beanFactory.ignoreDependencyInterface(EmbeddedValueResolverAware.class ) ; beanFactory.ignoreDependencyInterface(ResourceLoaderAware.class ) ; beanFactory.ignoreDependencyInterface(ApplicationEventPublisherAware.class ) ; beanFactory.ignoreDependencyInterface(MessageSourceAware.class ) ; beanFactory.ignoreDependencyInterface(ApplicationContextAware.class ) ; beanFactory.registerResolvableDependency(BeanFactory.class , beanFactory ) ; beanFactory.registerResolvableDependency(ResourceLoader.class , this ) ; beanFactory.registerResolvableDependency(ApplicationEventPublisher.class , this ) ; beanFactory.registerResolvableDependency(ApplicationContext.class , this ) ; beanFactory.addBeanPostProcessor(new ApplicationListenerDetector(this )); if (beanFactory.containsBean("loadTimeWeaver" )) { beanFactory.addBeanPostProcessor(new LoadTimeWeaverAwareProcessor(beanFactory)); beanFactory.setTempClassLoader(new ContextTypeMatchClassLoader(beanFactory.getBeanClassLoader())); } if (!beanFactory.containsLocalBean("environment" )) { beanFactory.registerSingleton("environment" , this .getEnvironment()); } if (!beanFactory.containsLocalBean("systemProperties" )) { beanFactory.registerSingleton("systemProperties" , this .getEnvironment().getSystemProperties()); } if (!beanFactory.containsLocalBean("systemEnvironment" )) { beanFactory.registerSingleton("systemEnvironment" , this .getEnvironment().getSystemEnvironment()); } }
Spring Bean 初始化前阶段 BeanPostProcessor#postProcessBeforeInitialization
Spring Bean 初始化阶段 依次往下执行
注解 @Postconstructor
接口 InitializingBean
元信息配置 @Bean(init-method=”init”)
Spring Bean 初始化后阶段 BeanPostProcessor#postProcessAfterInitialization
Spring Bean 初始化完成阶段 SmartInitializingSingleton#afterSingletonsInstantiated
适合 ApplicationContext 中回调
Spring Bean 销毁前阶段 DestructionAwareBeanPostProcessor#postProcessBeforeDestruction
Spring Bean 销毁阶段 执行次序依次往下执行
@PreDestroy 标注方法
实现 DisposableBean 接口的 destroy() 方法
自定义销毁方法 (destroy-mehod)
Spring Bean 垃圾收集
Bean 垃圾回收(GC)
关闭 Spring 容器(应用上下文)
执行 GC
Spring Bean 覆盖的 finalize() 方法被回调
Spring 事务 来源于 https://juejin.cn/post/6844903608224333838#heading-9
人家是专门做面试方向的,可以关注公众号,支持一下 Java Guide,只是讲了最基本的 Java 面试题,还不错。
事务的特性(ACID)
原子性: 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;一致性: 执行事务前后,数据保持一致;隔离性: 并发访问数据库时,一个用户的事物不被其他事物所干扰,各并发事务之间数据库是独立的;持久性: 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
Spring事务管理接口:
PlatformTransactionManager: (平台)事务管理器TransactionDefinition: 事务定义信息(事务隔离级别、传播行为、超时、只读、回滚规则)TransactionStatus: 事务运行状态
所谓事务管理,其实就是“按照给定的事务规则来执行提交或者回滚操作”。
Spring并不直接管理事务,而是提供了多种事务管理器 ,他们将事务管理的职责委托给Hibernate或者JTA等持久化机制所提供的相关平台框架的事务来实现。 Spring事务管理器的接口是: org.springframework.transaction.PlatformTransactionManager ,通过这个接口,Spring为各个平台如JDBC、Hibernate等都提供了对应的事务管理器,但是具体的实现就是各个平台自己的事情了。
PlatformTransactionManager接口中定义了三个方法:
1 2 3 4 5 6 7 8 9 Public interface PlatformTransactionManager () ... { TransactionStatus getTransaction (TransactionDefinition definition) throws TransactionException ; void commit (TransactionStatus status) throws TransactionException void rollback (TransactionStatus status) throws TransactionException } 复制代码
Spring中PlatformTransactionManager根据不同持久层框架所对应的接口实现类,几个比较常见的如下图所示
TransactionDefinition接口介绍 事务管理器接口 PlatformTransactionManager 通过 getTransaction(TransactionDefinition definition) 方法来得到一个事务,这个方法里面的参数是 TransactionDefinition类 ,这个类就定义了一些基本的事务属性。
那么什么是事务属性呢?
事务属性可以理解成事务的一些基本配置,描述了事务策略如何应用到方法上。事务属性包含了5个方面。
TransactionDefinition接口中的方法如下: TransactionDefinition接口中定义了5个方法以及一些表示事务属性的常量比如隔离级别、传播行为等等的常量。
我下面只是列出了TransactionDefinition接口中的方法而没有给出接口中定义的常量,该接口中的常量信息会在后面依次介绍到。
1 2 3 4 5 6 7 8 9 10 11 12 public interface TransactionDefinition int getPropagationBehavior () int getIsolationLevel () String getName () ; int getTimeout () ; boolean isReadOnly () }
事务隔离级别: 并发事务带来的问题 在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务(多个用户对统一数据进行操作)。并发虽然是必须的,但可能会导致一下的问题。
脏读(Dirty read): 当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提交到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是“脏数据”,依据“脏数据”所做的操作可能是不正确的。
丢失修改(Lost to modify): 指在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。
例如:事务1读取某表中的数据A=20,事务2也读取A=20,事务1修改A=A-1,事务2也修改A=A-1,最终结果A=19,事务1的修改被丢失。
不可重复读(Unrepeatableread): 指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。
幻读(Phantom read): 幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
不可重复度和幻读区别:
不可重复读的重点是修改,幻读的重点在于新增或者删除。
例1(同样的条件, 你读取过的数据, 再次读取出来发现值不一样了 ):事务1中的A先生读取自己的工资为 1000的操作还没完成,事务2中的B先生就修改了A的工资为2000,导 致A再读自己的工资时工资变为 2000;这就是不可重复读。
例2(同样的条件, 第1次和第2次读出来的记录数不一样 ):假某工资单表中工资大于3000的有4人,事务1读取了所有工资大于3000的人,共查到4条记录,这时事务2 又插入了一条工资大于3000的记录,事务1再次读取时查到的记录就变为了5条,这样就导致了幻读。
隔离级别 TransactionDefinition 接口中定义了五个表示隔离级别的常量:
TransactionDefinition.ISOLATION_DEFAULT: 使用后端数据库默认的隔离级别,Mysql 默认采用的 REPEATABLE_READ隔离级别 Oracle 默认采用的 READ_COMMITTED隔离级别.TransactionDefinition.ISOLATION_READ_UNCOMMITTED: 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读 TransactionDefinition.ISOLATION_READ_COMMITTED: 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生 TransactionDefinition.ISOLATION_REPEATABLE_READ: 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。 TransactionDefinition.ISOLATION_SERIALIZABLE: 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读 。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
事务传播行为(为了解决业务层方法之间互相调用的事务问题): 当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行。在TransactionDefinition定义中包括了如下几个表示传播行为的常量:
支持当前事务的情况:
TransactionDefinition.PROPAGATION_REQUIRED: 如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。TransactionDefinition.PROPAGATION_SUPPORTS: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。TransactionDefinition.PROPAGATION_MANDATORY: 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)
不支持当前事务的情况:
TransactionDefinition.PROPAGATION_REQUIRES_NEW: 创建一个新的事务,如果当前存在事务,则把当前事务挂起。TransactionDefinition.PROPAGATION_NOT_SUPPORTED: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。TransactionDefinition.PROPAGATION_NEVER: 以非事务方式运行,如果当前存在事务,则抛出异常。
其他情况:
TransactionDefinition.PROPAGATION_NESTED: 如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于TransactionDefinition.PROPAGATION_REQUIRED。
这里需要指出的是,前面的六种事务传播行为是 Spring 从 EJB 中引入的,他们共享相同的概念。而 PROPAGATION_NESTED 是 Spring 所特有的。以 PROPAGATION_NESTED 启动的事务内嵌于外部事务中(如果存在外部事务的话),此时,内嵌事务并不是一个独立的事务,它依赖于外部事务的存在,只有通过外部的事务提交,才能引起内部事务的提交,嵌套的子事务不能单独提交。如果熟悉 JDBC 中的保存点(SavePoint)的概念,那嵌套事务就很容易理解了,其实嵌套的子事务就是保存点的一个应用,一个事务中可以包括多个保存点,每一个嵌套子事务。另外,外部事务的回滚也会导致嵌套子事务的回滚。
事务超时属性(一个事务允许执行的最长时间) 所谓事务超时,就是指一个事务所允许执行的最长时间,如果超过该时间限制但事务还没有完成,则自动回滚事务。在 TransactionDefinition 中以 int 的值来表示超时时间,其单位是秒。
事务只读属性(对事物资源是否执行只读操作) 事务的只读属性是指,对事务性资源进行只读操作或者是读写操作。所谓事务性资源就是指那些被事务管理的资源,比如数据源、 JMS 资源,以及自定义的事务性资源等等。如果确定只对事务性资源进行只读操作,那么我们可以将事务标志为只读的,以提高事务处理的性能。在 TransactionDefinition 中以 boolean 类型来表示该事务是否只读。
回滚规则(定义事务回滚规则) 这些规则定义了哪些异常会导致事务回滚而哪些不会。默认情况下,事务只有遇到运行期异常时才会回滚,而在遇到检查型异常时不会回滚(这一行为与EJB的回滚行为是一致的)。 但是你可以声明事务在遇到特定的检查型异常时像遇到运行期异常那样回滚。同样,你还可以声明事务遇到特定的异常不回滚,即使这些异常是运行期异常。
TransactionStatus接口介绍 TransactionStatus 接口用来记录事务的状态 该接口定义了一组方法,用来获取或判断事务的相应状态信息.
PlatformTransactionManager.getTransaction(…) 方法返回一个 TransactionStatus 对象。返回的TransactionStatus 对象可能代表一个新的或已经存在的事务(如果在当前调用堆栈有一个符合条件的事务)。
TransactionStatus接口接口内容如下:
1 2 3 4 5 6 7 public interface TransactionStatus boolean isNewTransaction () boolean hasSavepoint () void setRollbackOnly () boolean isRollbackOnly () boolean isCompleted; }
AOP原理 首先,这只能作用于方法层级上面,字段层级不行 。Spring AOP 离开了 IoC 容器,就没有所谓的 AOP ,具体的是在 Bean 实例化前,实现了 SmartInstantiationAwareBeanPostProcessor 的 AbstractAdvisorAutoProxyCreator 3个实现类来搞的。AnnotationAwareAspectJAutoProxyCreator、DefaultAdvisorAutoProxyCreator、InfrastructureAdvisorAutoProxyCreator。
Java 的 Proxy 或者 CGLIB(ASM)动态代理,实现 AOP,做方法前后等增强。各种 Advisor 增强。
前者是必须有接口,用实现同一个接口的生成类替换原来的类。后者是生成其子类,来增强原有类,所以 final 方法会被代理失效。
https://juejin.im/post/5bf4fc84f265da611b57f906
JDK动态代理和cglib的实现的区别 一个是接口,一个做它的子类,对原有类型进行提升
JDK动态代理实现 Proxy.newInstance
CGLIB 实现动态代理 本质上是实现一个子类,去提升该类的方法。所以不要将类或方法设置成 final 类型的,类设置了会报错,作为不了他的子类,方法设置成 final,只能 invoke 不能增强该方法 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import org.springframework.cglib.proxy.Enhancer;import org.springframework.cglib.proxy.MethodInterceptor;public class CGLIBDemo public static void main (String[] args) Enhancer enhancer = new Enhancer(); enhancer.setSuperclass(CGLIBDemo.class ) ; enhancer.setCallback((MethodInterceptor) (o, method, objects, methodProxy) -> { System.err.println("Before invoke " + method); Object result = methodProxy.invokeSuper(o, objects); System.err.println("After invoke" + method); return result; }); CGLIBDemo cglibDemo = (CGLIBDemo) enhancer.create(); cglibDemo.test(); System.out.println(cglibDemo); } public void test () System.out.println("I'm test method" ); } }
Javassist 动态生成字节码 其实还是基于 ASM 来做的。
Ljava.lang.String
这种,直接生成 class 文件,织入 [Ljava.lang.String 这种代码,来在虚拟机内部动态生成 class 文件。
Spring 是如何解决循环依赖的 首先 prototype 不让循环依赖
其次是构造器注入依赖,必须提供无参构造器,让 bean 能够实例化,如果没有,那也会报错。
最终,Spring 会先实例化对象,将对象放入 earlySingletonObjects 中,如果循环依赖开始,优先查找 earlySingletonObjects。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class DefaultSingletonBeanRegistry extends SimpleAliasRegistry implements SingletonBeanRegistry private final Map<String, Object> singletonObjects = new ConcurrentHashMap(256 ); private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap(16 ); private final Map<String, Object> earlySingletonObjects = new HashMap(16 ); private final Set<String> registeredSingletons = new LinkedHashSet(256 ); private final Set<String> singletonsCurrentlyInCreation = Collections.newSetFromMap(new ConcurrentHashMap(16 )); private final Set<String> inCreationCheckExclusions = Collections.newSetFromMap(new ConcurrentHashMap(16 )); @Nullable private Set<Exception> suppressedExceptions; private boolean singletonsCurrentlyInDestruction = false ; private final Map<String, Object> disposableBeans = new LinkedHashMap(); private final Map<String, Set<String>> containedBeanMap = new ConcurrentHashMap(16 ); private final Map<String, Set<String>> dependentBeanMap = new ConcurrentHashMap(64 ); private final Map<String, Set<String>> dependenciesForBeanMap = new ConcurrentHashMap(64 ); public DefaultSingletonBeanRegistry () } }
所有面试题
https://blog.csdn.net/ThinkWon/article/details/104391081
Spring MVC Spring MVC 具体请求执行过程 handlerMapping -> handler ->
其实看 DispatherServlet#doService 方法就行了。所谓的图,不懂的人,还是看不懂的,看源代码就知道了。
前置知识是 MethodHandler
Spring Cloud
Spring Cloud Netflix
Spring Cloud Alibaba
Spring Cloud Azure
Spring Cloud Amazon
Spring Cloud HUAWEI
其实 Spring Cloud Alibaba 开源,是为了更好的卖自家的云产品,例如 RocketMQ,大厂没有什么真正开源,就是为了钱罢了,用爱发电这种事,大家都比较难做。
Eureka/Nacos Spring Cloud 服务注册、服务发现几个抽象。
DiscoveryClient、ServiceInstance
租约机制。
Eureka 实现了 AP。任何 Server 都是主 Server,Server 与 Server 之间同步需要时间,可能会出现不一致的情况。Consistency
Nacos 实现了两种 AP,CP 模式,需要哪种可以指定。
Feign/Dubbo 前者使用 HTTP 协议,更为通用,适合不是那么注重性能的场景或者需要跨语言的场景。
虽然 Dubbo 协议也支持,但不是支持所有语言。
Hystrix/Sentinel(哨兵) Sentinel 除了熔断限流,还有分布式应用监控的功能
Gateway/Zuul RocketMQ 我选择 Confluent Kafka
分布式服务配置中心 Apollo 挺好用,隔离机制,以及发布信息等做的挺好,就是要配置 MySQL,启动三个不同的 jar,内部实现是 Eureka + http long polling 长连接。
Spring Cloud Config Nacos MyBatis MyBatis缓存机制 一级缓存 基于 PerpetualCache 的 HashMap 本地缓存, 其存储作用域为 Session, 当 Session flush 或 close 之后, 该 Session 中的所有 Cache 就 将清空, 默认打开一级缓存。
二级缓存 与一级缓存其机制相同, 默认也是采用 PerpetualCache, HashMap 存储, 不同在于其存储作用域为 Mapper(Namespace), 并且可自定义存储源, 如 Ehcache。 默认不打开二级缓存, 要开启二级缓存, 使用二级缓存属性类需要实 现 Serializable 序列化接口(可用来保存对象的状态),可在它的映射文件中配置
就是跨 SqlSession 的缓存,生产上不建议开启。
设计模式 简单工厂模式 定义 简单工厂模式又叫静态方法模式。
补充:根据输入参数,或调用不同静态方法创建不同类型实例。
示例代码 单例模式 定义 应用场景 注意事项
对于初始化耗时的类来说,饿汉式单例更适合。
Spring 采用 Hash 散列表来实现单例,自己 new [SpringBean] 还是会创建不同对象。
示例代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class Singleton private static Singleton instance; private Singleton () if (instance != null ){ throw new IllegalAccessException(); } } public static Singleton getInstance () if (instance == null ){ synchronized (Singleton.class ) { if (instance == null ){ instance = new Singleton(); } } } return instance; } }
构建器模式 定义 将一个复杂对象的构建与其表示相分离,使得同样的构建过程(稳定)可以创建不同的表示(变化)。
应用场景 https://time.geekbang.org/column/article/199674
我们把类的必填属性放到构造函数中,强制创建对象的时候就设置。如果必填的属性有很多,把这些必填属性都放到构造函数中设置,那构造函数就又会出现参数列表很长的问题。如果我们把必填属性通过 set() 方法设置,那校验这些必填属性是否已经填写的逻辑就无处安放了。
如果类的属性之间有一定的依赖关系或者约束条件,我们继续使用构造函数配合 set() 方法的设计思路,那这些依赖关系或约束条件的校验逻辑就无处安放了。
如果我们希望创建不可变对象,也就是说,对象在创建好之后,就不能再修改内部的属性值,要实现这个功能,我们就不能在类中暴露 set() 方法。构造函数配合 set() 方法来设置属性值的方式就不适用了
示例代码 另外,MyBatis 也有 SqlSessionFactoryBuilder 来构建 SqlSessionFactory(虽然也可以用 Java Bean 的方式)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 public final class BeanDefinitionBuilder private final AbstractBeanDefinition beanDefinition; private int constructorArgIndex; public static BeanDefinitionBuilder genericBeanDefinition (String beanClassName) BeanDefinitionBuilder builder = new BeanDefinitionBuilder(new GenericBeanDefinition()); builder.beanDefinition.setBeanClassName(beanClassName); return builder; } public BeanDefinitionBuilder setInitMethodName (@Nullable String methodName) this .beanDefinition.setInitMethodName(methodName); return this ; } public BeanDefinitionBuilder setDestroyMethodName (@Nullable String methodName) this .beanDefinition.setDestroyMethodName(methodName); return this ; } public BeanDefinitionBuilder setScope (@Nullable String scope) this .beanDefinition.setScope(scope); return this ; } public AbstractBeanDefinition getBeanDefinition () this .beanDefinition.validate(); return this .beanDefinition; } } public class BeanDefinitionAPI public GenericBeanDefinition getGeneriBeanDefinition () return (GenericBeanDefinition)BeanDefinitionBuilder .genericBeanDefinition("org.springframework.web.client.RestTemplate" ) .setScope("singleton" ) .getBeanDefinition(); } }
原型模式 代理模式 桥接模式 适配器模式 门面模式 组合模式 享元模式 迭代器模式 JDK 源码用到了哪些设计模式 https://blog.csdn.net/baiye_xing/article/details/76427717
MySQL/Oracle 一条 SQL 的执行过程 来源于这个大佬的 https://www.processon.com/view/link/5f27c4e17d9c0835d3a35995
词法解析 -> 如果开启了缓存(5.7后默认关闭),如果没有修改内容,则返回结果 -> 词法解析生成树 -> 调用 innodb ->
事务隔离级别 读未提交 Read Uncommitted
读已提交 Read Committed
可重复读 Repeatable Read
串行化 Serializable
分别解决了事务执行的不同情况。
这些是事务型数据库设计的基本概念
通过 Explain 分析并优化 SQL 两年前使用 PL/SQL 对慢 SQL 的解释查询计划小优化。其实还有其他的 SQL 优化,没展示出来,项目后期帮其他组员重构优化代码和 SQL。
https://yq.aliyun.com/articles/687976?spm=a2c4e.11155435.0.0.5f4633120ERia8
还有 like ‘%xx%’, like ‘xx%’, like ‘%xx’
我把其他组员的第一个改成了第二个,因为第二个能用到索引。这也是优化 SQL 的一个小技巧。
具体原因,是因为根据 ASCII 比对的,比对成了就返回。有前缀索引内味了。
BaiKalDB 百度开源的,基于 MySQL 以及 RocksDB 实现的分布式数据库。通过 Partition Region 的概念实现,理论上没有存储瓶颈。
有点像 TiDB,也被人说是 C++ 版本的 TiDB。
这个 RocksDB 也被用于 Pika 中,是一种高效的且大容量的 NoSQL 数据库。
OceanBase 阿里开源的数据库。
Redis Reids 6 个底层数据结构
简单动态字符串 SDS
List 双向链表
ZipList 压缩列表
SkipList 跳表
HashMap 哈希表
整数数组
Redis 是一个主要由 Salvatore Sanfilippo(Antirez)开发的开源内粗数据结构存储器。因为其丰富的数据类型结构的值,可以被用作缓存、数据库、分布式锁和消息队列等1
Redis 包含了 5 种的基本数据类型
String
Hash
List
Set
SortedSet
和四个特殊的数据类型
HyperLogLog
BitMap
GEO(地理坐标)
Steam(流)
注意,这个 5 种的基本数据类型不代表它的具体实现。它的具体实现是根据值的大小,而不同的。下面有个图2
可以看出来,除了它的表面上的对应的实现,还有压缩列表这个数据结构(ZipList),在它的值到达一定阈值时 ,会自动转换为其表面的实现。
其实可以这么记,String 就是 Simple Dynamic String,Set 是哈希表和整数数组,List 、SortedList 和 Hash 在一定阈值后变成其对应实现。List -> 双向链表,Hash -> 哈希表,SortedSet -> 跳表.
下面是 Redis 6.0.5 的 redis.conf 的配置及其注释(可以跳过不看)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 hash-max-ziplist-entries 512 hash-max-ziplist-value 64 list-max-ziplist-size -2 set-max-intset-entries 512 zset-max-ziplist-entries 128 zset-max-ziplist-value 64
下面我讲下对应的数据类型及其数据结构实现
Redis 全局 Hash 表总览 为了实现从键到值的快速访问,Redis 使用了一个哈希表来保存所有键值对。
一个哈希表,其实就是一个数组,数组的每个元素称为一个哈希桶。所以,我们常说,一个哈希表是由多个哈希桶组成的,每个哈希桶中保存了键值对数据。
哈希桶中的元素保存的并不是值本身,而是指向具体值的指针。指针你懂我意思吧,就是个内存地址,并不是实际内容。这个其实就是 HashMap,讲这个,就顺便复习下 HashMap 的东西。tips:这里的 *key 其实是 c++ 里面的声明变量的方式。和 Java 里面的 String s 这种类似
HashTable 问题 这里其实 Java 里面的本来应该常用哈希表(HashTable)的,这里的哈希表和 Java HashMap 实现是差不多的。后者是双向链表(过一定阈值)转红黑树。
1. 哈希冲突 哈希冲突就是 12%6 = 0,24%6 = 0,或者两个不同的键算出了同样的哈希值。单单靠计算哈希值然后取模的方式,不同的键值肯定会存在一样的取模后的值。所以哈希表里面就会用往下加 。但是这个往下加也有个限度,它会一个个加,加到 10w 个,那就要往下找 10w 次,对本来是 O(1) 查找速度的数据结构肯定接受不了。在 Java 的 HashMap 中,如果单个链表长度过长,则会进行扩容,在其中进行 rehash 。
2. rehash 为了解决那么多的节点可能出现在哈希表的一个下标下,那么就需要 rehash 来重新调整哈希表的大小,即数组大小。
为了使 rehash 操作更高效,Redis 默认使用了两个全局哈希表:哈希表 1 和哈希表 2。一开始,当你刚插入数据时,默认使用哈希表 1,此时的哈希表 2 并没有被分配空间。随着数据逐步增多,Redis 开始执行 rehash,这个过程分为三步[3] :
给哈希表 2 分配更大的空间,例如是当前哈希表 1 大小的两倍;
把哈希表 1 中的数据重新映射并拷贝到哈希表 2 中;
释放哈希表 1 的空间。
到此,我们就可以从哈希表 1 切换到哈希表 2,用增大的哈希表 2 保存更多数据,而原来的哈希表 1 留作下一次 rehash 扩容备用。
这个过程看似简单,但是第二步涉及大量的数据拷贝,如果一次性把哈希表 1 中的数据都迁移完,会造成 Redis 线程阻塞,无法服务其他请求。此时,Redis 就无法快速访问数据了。为了避免这个问题,Redis 采用了渐进式 rehash 。
简单来说就是在第二步拷贝数据时,Redis 仍然正常处理客户端请求,每处理一个请求时,从哈希表 1 中的第一个索引位置开始,顺带着将这个索引位置上的所有 entries 拷贝到哈希表 2 中;等处理下一个请求时,再顺带拷贝哈希表 1 中的下一个索引位置的 entries。 如下图所示:
压缩列表 ZipList 介绍 压缩列表是Redis为了节约内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型(sequential)数据结构。一个压缩列表可以包含任意多个节点(entry),每个节点可以保存一个字节数组或者一个整数值。
压缩列表实际上类似于一个数组,数组中的每一个元素都对应保存一个数据。和数组不同的是,压缩列表在表头有三个字段 zlbytes、zltail 和 zllen,分别表示列表长度、列表尾的偏移量和列表中的 entry 个数;压缩列表在表尾还有一个 zlend,表示列表结束。
在压缩列表中,如果我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段的长度直接定位,复杂度是 O(1)。而查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N) 了。
下面不是重点可以跳过
属性
类型
长度
用途
zlbytes
unit32_t
4字节
记录整个压缩列表占用的内存字节数;在对压缩列表进行内存重分配,或者计算 zlend 的位置时使用。
zltail
unit32_t
4字节
记录压缩列表表尾节点距离压缩列表的起始地址有多少字节:通过这个偏移量,程序无需遍历压缩列表就可以确定表尾节点的地址。
zllen
unit16_t
2字节
记录了压缩列表包含的节点数量:当这个属性的值小于 UINT16_MAX(65535)时,这个属性的值就是压缩力表包含节点的数量;等于时,节点的真实数量需要遍历整个压缩列表才能计算得出。(所以压缩列表节点数不宜过大 )
entryX
列表节点
不确定
压缩列表包含的各个节点,节点的长度由节点保存的内容决定
zlend
unit8_t
1字节
特殊值 0xFF (十进制 255),用于标记和压缩列表的末端
下面是一个压缩列表的样例[4]
列表zlbytes属性的值为0xd2(十进制210),表示压缩列表的总长为210字节。
列表zltail属性的值为0xb3(十进制179),这表示如果我们有一个指向压缩列表起始地址的指针p,那么只要用指针p加上偏移量179,就可以计算出表尾节点entry5的地址。
列表zllen属性的值为0x5(十进制5),表示压缩列表包含五个节点。
压缩列表节点数不宜过大!!!
跳表 SkipList 跳表在链表的基础上,增加了多级索引,通过索引位置的几个跳转,实现数据的快速定位。
跳跃表(SkipList)是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。
跳跃表支持平均 O(logN)、最坏 O(N)复杂度的节点查找,还可以通过顺序性操作来批量处理节点。
在大部分情况下,跳跃表的效率可以和平衡树相媲美,并且因为跳跃表的实现比平衡树要来得更为简单,所以有不少程序都使用跳跃表来代替平衡树。
和链表、字典等数据结构被广泛地应用在Redis内部不同,Redis只在两个地方用到了跳跃表 ,一个是实现有序集合键 ,另一个是在集群节点中用作内部数据结构 ,除此之外,跳跃表在Redis里面没有其他用途。
下面是演示跳表找一个节点。以此类推,三级索引,N 级索引。当数据量很大时,跳表的查找复杂度就是 O(logN)。
更为详细的跳表介绍 (可以不看)
还有,为什么选择跳表而不是平衡树,看这个解释 (可以跳过不看 )
数据结构的时间复杂度
名称
时间复杂度
哈希表
O(1)
跳表
O(logN)
双向链表
O(N)
压缩列表
O(N)
整数列表
O(N)
不同操作的复杂度 不同操作的复杂度集合类型的操作类型很多,有读写单个集合元素的,例如 HGET、HSET,也有操作多个元素的,例如 SADD,还有对整个集合进行遍历操作的,例如 SMEMBERS。这么多操作,它们的复杂度也各不相同。而复杂度的高低又是我们选择集合类型的重要依据。
单元素操作,是指每一种集合类型对单个数据实现的增删改查操作。 例如,Hash 类型的 HGET、HSET 和 HDEL,Set 类型的 SADD、SREM、SRANDMEMBER 等。这些操作的复杂度由集合采用的数据结构决定,例如,HGET、HSET 和 HDEL 是对哈希表做操作,所以它们的复杂度都是 O(1);Set 类型用哈希表作为底层数据结构时,它的 SADD、SREM、SRANDMEMBER 复杂度也是 O(1)。集合类型支持同时对多个元素进行增删改查,例如 Hash 类型的 HMGET 和 HMSET,Set 类型的 SADD 也支持同时增加多个元素。此时,这些操作的复杂度,就是由单个元素操作复杂度和元素个数决定的。例如,HMSET 增加 M 个元素时,复杂度就从 O(1) 变成 O(M) 了。 范围操作,是指集合类型中的遍历操作,可以返回集合中的所有数据 ,比如 Hash 类型的 HGETALL 和 Set 类型的 SMEMBERS,或者返回一个范围内的部分数据,比如 List 类型的 LRANGE 和 ZSet 类型的 ZRANGE。这类操作的复杂度一般是 O(N),比较耗时,我们应该尽量避免。 Redis 从 2.8 版本开始提供了 SCAN 系列操作(包括 HSCAN,SSCAN 和 ZSCAN),这类操作实现了渐进式遍历,每次只返回有限数量的数据。统计操作, 是指集合类型对集合中所有元素个数的记录 ,例如 LLEN 和 SCARD。这类操作复杂度只有 O(1),这是因为当集合类型采用压缩列表、双向链表、整数数组这些数据结构时,这些结构中专门记录了元素的个数统计,因此可以高效地完成相关操作。例外情况, 是指某些数据结构的特殊记录,例如压缩列表和双向链表都会记录表头和表尾的偏移量 。这样一来,对于 List 类型的 LPOP、RPOP、LPUSH、RPUSH 这四个操作来说,它们是在列表的头尾增删元素,这就可以通过偏移量直接定位,所以它们的复杂度也只有 O(1),可以实现快速操作。
参考
《Redis 使用手册》
极客时间《Redis 核心技术实战》
Redis单线程 所谓的单线程,其实是指 Redis 对读和写键值的时候是单线程操作(这里就会导致某个命令如果执行耗时过长,会导致 Redis 实例卡住),和传统的 Socket 单线程 accept 接收不同。Redis 采用了 select/epoll IO多路复用的方式,将所有到达的 TCP 请求,进行了汇总到事件队列中,然后由 Redis 主线程一条条执行命令。
所谓单线程,是指网络 IO 和键值对读写是由一个线程来完成的。用于集群数据同步、持久化(save/bgsave)、异步删除都是由其他线程来完成的。
Redis6 默认为关闭,需手动设置开启
即使开启了多线程,Redis 对读和写键值的时候,还是单线程了,只不过是多线程接受消息。
Redis 哨兵集群 一主多从,客观下线
// TODO 判断过程
Redis 分片 16384个哈希槽,CRC16
Codis
// TODO 分配哈希槽命令
Redis 集群同步 一主多从,RDB 同步
replica buf,以及对应的 log
// TODO 同步步骤
Redis 源码优化 利用 taskset 将主线程进行绑核操作。
lscpu 查看 cpu 是不是 numa 架构,来进行 CPU 绑核操作。华为的 OpenGuass 数据库也是利用了这个绑核操作,在数据库启动的时候就会自动绑核做极致优化。
Netty ByteBuf 数据的容器,具体方法,里面有读指针和写指针等。
InboundChannel 入站管道。
ChannelPipeline Netty Zero Copy 少了两步骤,调用的操作系统的复制方法。
少了用户态的参与。
https://zhuanlan.zhihu.com/p/78869158
Netty 解决粘包 使用复杂的协议,进行拆包。
数据结构 二叉树遍历 前序:根左右
中序:左根右
后序:左右根
二叉树 1 2 3 4 5 6 7 8 9 10 11 public class Node Node left, right; int val; public Node (int val) this .val = val; } }
前序遍历 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public List<Integer> preorderTraversal (TreeNode root) List<Integer> res = new LinkedList(); LinkedList<TreeNode> stack = new LinkedList(); if (root == null ){ return res; } stack.add(root); while (!stack.isEmpty()){ TreeNode node = stack.pollLast(); res.add(node.val); if (node.right != null ){ stack.add(node.right); } if (node.left != null ){ stack.add(node.left); } } return res; }
求二叉树最大深度 1 2 3 4 5 6 7 8 9 10 public int maxDepth (TreeNode root) if (root == null ) { return 0 ; } int leftHeight = maxDepth(root.left); int rightHeight = maxDepth(root.right); return Math.max(leftHeight, rightHeight) + 1 ; }
算法 冒泡排序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public void sort (int [] arr) int size = arr.length; int i, j; int k = size - 1 , pos = 0 ; for (i = 0 ; i < size - 1 ; i++) { int flag = 0 ; for (j = 0 ; j < k; j++) { if (arr[j] > arr[j + 1 ]) { int tmp = arr[j]; arr[j] = arr[j + 1 ]; arr[j + 1 ] = tmp; flag = 1 ; pos = j; } } k = pos; if (flag == 0 ) { return ; } } }
演示动态图
快速排序 二分搜索 插入排序 insert 归并排序 merge 选择排序 select LeetCode 刷题 滑动窗口寻找字符串 大型分布式网站架构 架构 单体 -> SOA -> 微服务 -> Serveless
下一代架构,Serveless
负载均衡策略
轮询(Round Robin)
随机
hash 取模
加权轮询(和轮询一样,只不过根据权重,重复的IP地址根据权重变成多份)
加权随机
最小连接数
动态选择连接数最小服务器
常见权限设计
ACL:Access-Control List,访问控制列表。
RBAC:Role-Based Access Control,基于角色的权限控制。
ABAC:Attribute-Based Access Control,基于属性的权限控制。
PBAC:Policy-Based Access Control,基于策略的权限控制。
ACL示例:MySQL,MongoDB,HBase 都是以 ACL 作为权限控制思想,MySQL 在赋予用户权限时,有个 acl_users 数组进行存储 all_user 信息(不仅在 mysql.user 这个表里加数据)。
RBAC示例:常见的权限系统,在 人员 1<–>n 角色 1<–>n 权限。
OAuth2 https://www.ruanyifeng.com/blog/2014/05/oauth_2_0.html
阮一峰大佬的云冲印的例子。
其实现 Spring Security Oauth2
如何设计海量数据的存储系统 参考 TiDB,或者 GFS 升级版 Colossus(套娃)。
Consistent Hash 一致性哈希 基础:将 Hash 函数的值域空间组织成一个圆环,计算出对应的 key 的 hash 值在环上对应的区间。
进阶:对每个节点进行计算多个 Hash 值,引入虚拟节点,虚拟节点映射到真实节点。
https://www.infoq.cn/article/7cBOXVbB6B5V0BJh6Rfx
缓存的实现原理,设计缓存要注意什么 https://juejin.im/post/5b849878e51d4538c77a974a
进程内缓存Guava cache 、Ecache,也可以使用其提供的同步机制同步多个进程间缓存。
// TODO《深入分布式缓存》
操作系统的页式存储 https://www.tomorrow.wiki/archives/334
page cache。最好不要改,redis 利用 page cache 做了优化,改大了影响性能。
// TODO 详细解释 page cache
分布式Session
HTTP 请求的过程与原理
DNS解析
TCP连接
发送HTTP请求
服务器处理请求并返回HTTP报文
浏览器解析渲染页面
连接结束
TCP 连接的特点
TCP如何保证安全可靠的 ACK机制,三次握手,四次挥手
UDP 基础知识 无连接协议即用户数据报协议(UDP),通常在性能至关重要并且能够容忍一定的数据包丢失的情况下。用户数据报协议 (英语:U ser D atagram P rotocol,缩写:UDP ;又称用户数据包协议 )是一个简单的面向数据报 的通信协议 ,位于OSI模型 的传输层 。该协议由David P. Reed 在1980年设计且在RFC 768 中被规范。典型网络上的众多使用UDP协议的关键应用在一定程度上是相似的。
在TCP/IP 模型中,UDP为网络层 以上和应用层 以下提供了一个简单的接口。UDP只提供数据 的不可靠传递,它一旦把应用程序发给网络层的数据发送出去,就不保留数据备份(所以UDP有时候也被认为是不可靠的数据报协议)。UDP在IP数据报的头部仅仅加入了复用和数据校验字段。
UDP适用于不需要或在程序 中执行错误检查和纠正 的应用 ,它避免了协议栈 中此类处理的开销 。对时间有较高要求的应用程序通常使用UDP,因为丢弃数据包比等待或重传导致延迟更可取。
UDP 的可靠性 由于UDP缺乏可靠性 且属于无连接 协议,所以应用程序通常必须容许一些丢失 、错误或重复的数据包 。某些应用程序(如TFTP )可能会根据需要在应用程序层中添加基本的可靠性机制。[1]
一些应用程序不太需要可靠性机制,甚至可能因为引入可靠性机制而降低性能,所以它们使用UDP这种缺乏可靠性的协议。流媒体,实时多人游戏和IP语音(VoIP )是经常使用UDP的应用程序。 在这些特定应用中,丢包通常不是重大问题。如果应用程序需要高度可靠性,则可以使用诸如TCP 之类的协议。
例如,在VoIP中延迟 和抖动 是主要问题。如果使用TCP,那么任何数据包丢失或错误都将导致抖动,因为TCP在请求及重传丢失数据时不向应用程序提供后续数据。如果使用UDP,那么应用程序则需要提供必要的握手,例如实时确认已收到的消息。
由于UDP缺乏拥塞控制 ,所以需要基于网络的机制来减少因失控和高速UDP流量负荷而导致的拥塞崩溃效应。换句话说,因为UDP发送端无法检测拥塞,所以像使用包队列和丢弃技术的路由器之类的网络基础设备会被用于降低UDP过大流量。数据拥塞控制协议 (DCCP)设计成通过在诸如流媒体类型的高速率UDP流中增加主机拥塞控制,来减小这个潜在的问题。
UDP 应用 许多关键的互联网应用程序使用UDP[2] ,包括:
流媒体 、在线游戏 流量通常使用UDP传输。 实时视频流和音频流应用程序旨在处理偶尔丢失、错误的数据包,因此只会发生质量轻微下降,而避免了重传数据包 带来的高延迟 。 由于TCP和UDP都在同一网络上运行,因此一些企业发现来自这些实时应用程序的UDP流量影响了使用TCP的应用程序的性能,例如销售 、会计 和数据库系统 。 当TCP检测到数据包丢失时,它将限制其数据速率使用率。由于实时和业务应用程序对企业都很重要,因此一些人认为开发服务质量 解决方案至关重要。[3]
详情
TCP 是面向连接的传输,管理了两个端点之间的连接的建立,在连接的生命周期内的有序和可靠的消息传输,以及最后,连接的有序终止。相比之下,在类似于 UDP 这样的无连接协议中,并没有持久化连接的概念,并且每个消息(一个 UDP 数据报)都是一个单独的传输单元。
UDP 没有 TCP 的纠错机制,其中每个节点都将确认它们所接收到的包,而没有被确认的包会被发送方重新传输。
UDP 广播 UDP 提供了向多个接收者发送消息的额外传输模式
服务稳定性 依赖管理 理清调用链路、流量控制、慢调用降级。
优雅降级 为避免单个服务实例宕机导致服务雪崩,通常有集群管理或服务熔断机制,可以两个一起用。Dubbo 服务设置里面手动设置阈值。
服务分级 对服务实例设置白名单机制,对不同服务进行分级处理,优先处理等级高的服务请求。我觉得可以把调用失败的请求,转到 mq 上,由一群专门用于处理调用失败请求的服务,进行定时执行从 mq 尝试拉取失败请求,进行重试。
开关 如果服务消费者 A、B、C 都依赖服务提供者 D,如果前面做了服务分级,则可以在实例负载超过警戒水位线,进行关闭对低优先级的请求。
应急预案 提前做好扩容方案。
Sentinel 都符合了这些要求(应急预案不含)。本质上都是舍车保帅,保证能用的服务不挂,保证优先级高的服务能用,提前准备应对方案。
高并发系统设计 操作原子性 volatile,synchronized
多线程同步 JUC
数据一致性 强一致性
要求无论数据的更新操作是在哪个副本上执行,之后所有的读操作都要能够获取到更新的最新数据。
弱一致性
系统的某个数据被更新后,后续对该数据的读取操作到的可能是更新前的值,也可能是更新后的值。全部用户完全读取到更新后的数据需要经过一段时间,这段时间称为“不一致性窗口”
最终一致性
最终一致性是弱一致性的特殊形式,这种情况下系统保证用户最终能够读取到某个操作对系统的更新,“不一致窗口”的时间依赖于网络的延迟、系统的负载和副本的个数。
系统的可扩展性 通过简单加机器,简单的配置就能实现更高吞吐量,那这就是易扩展。
并发减库存 https://time.geekbang.org/column/article/40743
减库存一般有三种
下单减库存 可以通过数据库事务控制,但是下了单不一定付款。
付款减库存 ,如果并发比较高,可能出现买家下单后付不了款的情况,因为商品已经被其他人买走了。
预扣库存 ,买家下单后,库存为其保留一定时间(如10分钟),超过这个时间,库存将会自动释放,释放后其他买家可以继续购买(有点锁的味道)。在买家付款前,系统会校验订单的库存是否还有保留,如果没有保留,则再次尝试预扣;如果库存不足(预扣失败),则不允许继续付款,如果预扣成功,则完成付款并实际地去减库存。
对商品剩余数量的查询,可以使用缓存 Ecache/Guava Cache 进行本地缓存返回。
应用层做排队。 按照商品维度设置队列顺序执行,这样能减少同一台机器对数据库同一行记录进行操作的并发度,同时也能控制单个商品占用数据库连接的数量,防止热点商品占用太多的数据库连接。
数据库层做排队 。阿里的数据库团队开发了针对这种 MySQL 的 InnoDB 层上的补丁程序(patch),可以在数据库层上对单行记录做到并发排队。
性能优化措施 前端性能优化
页面的 HTTP 请求数量(尽量减少请求数量,像QQ音乐网页版就是反例,大量无用的 debug 请求)
是否使用 CDN 网络(静态资源上 CDN)
是否使用压缩
Java 程序优化
合理使用单例模式。提升对象复用性,减少内存开销
Future 模式(FutureTask,异步执行任务)
线程池(避免对象频繁创建、销毁,使用池化思想,在任意时刻,每一个对象、连接、线程,并不会被多处使用,而是被一个使用者独占,当使用完成之后,放回到池中,再由其他使用者重复利用)
选择就绪(使用 NIO)
减少上下文切换 (2 * cpu核心数 * cpu核数 + 1,IO 密集型这么做,计算密集型 cpu 核心数+1)
降低锁竞争(1. 合理减少 synchronized 域的范围,2. 减小锁的粒度 3.使用读写锁比使用独占锁提供更高的并发量 )
压缩 HTTP Header gzip
结果缓存 从数据库开始使用缓存(不建议) -> 不建议使用 MyBatis 的二级缓存,进程内缓存 Guava cache,Ecache -> 跨进程缓存 (Redis ,对值结构;要求复杂点的系统不推荐Memcached)-> 静态资源缓存(CDN)
数据库查询性能优化
合理使用索引(explain,解释计划查询,对特定业务进行建立索引进行查询优化)例子 oracle 是 explain plan for
反范式设计(适当冗余字段,尽量避免多表操作)
使用查询缓存(不推荐,5.7 之后默认关闭,8.0 不准开,使用起来很多坑)
使用搜索引擎(Elasticsearch 加速 Like 查询以及很多复杂的查询)
使用 Key-Value 数据库(HBase, TDH 的 HyperBase,通过设计合理的 RowKey 加速查询)
GC 优化 分析 dump 日志,合理设置启动参数,Xms 设置为机器内存的 65% - 70%。
硬件性能提升 其实硬件性能提升是所有优化里面,能最简单,最大的优化。生产上都是 Nginx + F5 来提升单体应用。
Java 应用 CPU 使用率飙升故障排查 // TODO 把 19 年如何解决 CPU 使用率飙升的命令写出来
工具 Arthas
数据分析 使用Hadoop 进行数据分析。
Storm 是 2011 年 Twitter 开源的一个实时的分布式流式处理系统,有点类似于 Hadoop 提供的大数据解决方案,但是它要处理的对象是没有终点的数据流(也叫无界数据流),而非 Hadoop 的 MapReduce 那样的批处理系统。
日志收集系统 Chukwa 离线数据分析 数据同步 过程往往是从 OLTP 库中,以及日志系统中,提取和清洗(数据清洗可以用 Kafka Stream)所需要的数据到 OLAP 系统(所在的银行当前系统就是这样的)。构建在 hive 平台,然后在 OLAP 系统上进行多维度复杂的数据分析和汇总操作,利用这些数据构建数据报表,进行前端展示。我们做的是每天全量同步。使用的 Sqoop,没用 DataX 。
离线同步(全量同步) 使用 sqoop
实时同步(增量同步) 使用 MySQL 主从机制,通过伪装成从库进行 binlog —> Kafka (任意 MQ) —> 其他库
算是备忘录模式的体现,全量和增量。
Zookeeper Zookeeper 介绍 Zookeeper 是一个开源的分布式协调服务软件,它是集群的管理者,监视着集群中各个节点的状态根据节点提交的反馈进行下一步操作。最终,将简单易用的接口和性能高效,功能稳定的系统提供给用户。
分布式应用程序可以基于 Zookeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
Zookeeper 保证了分布式一致性特性:
顺序一致性
原子性
单一视图
可靠性
实时性(最终一致性)
Zookeeper 提供了什么?
文件系统
通知机制
Zookeeper 文件系统 Zookeeper 提供了一个多层级的节点命名空间(节点称为 znode)。与文件系统不同的是,这些节点都可以设置关联的数据,而文件系统中只有文件节点可以存放数据而目录节点不行。Zookeeper 为了保证高吞吐和低延迟,在内存中维护了这个树状目录结构,这种特性使得 Zookeeper不能用于存放大的数据,每个节点的存放数据上限为 1M。
ZAB 协议 ZAB 协议是为分布式协调服务 Zookeeper专门设计的一种支持崩溃恢复的原子广播协议。
ZAB协议包括两种基本的模式:崩溃恢复和消息广播。
当整个Zookeeper集群刚刚启动或者 Leader服务器宕机、重启或者网络故障导致不存在过半的服务器与Leader服务器保持正常通信时,所有进程(服务器)进入崩溃恢复模式,首先选举产生新的Leader服务器,然后集群中Follower服务器开始与新的Leader服务器进行数据同步,当集群中超过半数及其与该 Leader服务器完成数据同步之后,退出恢复模式进入消息广播模式,Leader服务器开始接收客户端的事务请求生成事务提案进行事务请求处理。
四种类型的数据节点 Znode PERSISTENT:持久节点,除非手动删除,否则节点一直存在于Zookeeper上
EPHEMERAL:临时节点 临时节点的生命周期与客户端会话绑定,一旦客户端会话失效(客户端与Zookeeper连接断开不宜一定会话失效),那么这个客户端创建的所有临时节点都会被移除。Kafka集群就是基于临时节点
PERSISTENT_SEQUENTIAL:持久顺序节点 基本特性同持久节点,只是增加了顺序属性,节点名后边会追加一个由父节点维护的自增整型数字
EPHEMERAL_SEQUENTIAL:临时顺序节点 基本特性同临时节点,增加了顺序属性,节点名后边会追加一个由副节点维护的自增整型数字。
ZooKeeper Wather 机制 – 数据变更通知 Zookeeper允许客户端向服务端的某个Znode注册一个Watcher监听,当服务端的一些指定事件触发了这个Watcher,服务端会向指定客户端发送一个事件通知来实现分布式的通知功能,然后客户端根据Watcher通知状态和事件类型做出业务上的改变。
工作机制 :
客户端注册watcher
服务端处理watcher
客户端回调watcher
Watcher特性总结 :
一次性
无论是服务端还是客户端,一旦一个Watcher被触发,Zookeeper都会将其从相应的存储中移除。这样的设计有效的减轻了服务端的压力,不然对于更新非常频繁的节点,服务端会不断的向客户端发送事件通知,无论对于网络还是服务端的压力都非常大。
客户端串行执行
客户端Watcher回调的过程是一个串行同步的过程。
轻量
Watcher通知非常简单,只会告诉客户端发生了事件,而不会说明事件的具体内容。
客户端向服务端注册Watcher的时候,并不会把客户端真实的Watcher对象实体传递到服务端,仅仅是在客户端请求中使用boolean类型属性进行了标记。
watcher event异步发送watcher的通知事件从server发送到client是异步的,这就存在一个问题,不同的客户端和服务器之间通过socket进行通信,由于网络延迟或其他因素导致客户端在不通的时刻监听到事件,由于Zookeeper本身提供了ordering guarantee,即客户端监听事件后,才会感知它所监视znode发生了变化。所以我们使用Zookeeper不能期望能够监控到节点每次的变化。Zookeeper只能保证最终的一致性,而无法保证强一致性。
注册watcher getData、exists、getChildren
触发watcher create、delete、setData
当一个客户端连接到一个新的服务器上时,watch将会被以任意会话事件触发。当与一个服务器失去连接的时候,是无法接收到watch的。而当client重新连接时,如果需要的话,所有先前注册过的watch,都会被重新注册。通常这是完全透明的。只有在一个特殊情况下,watch 可能会丢失:对于一个未创建的znode的exist watch,如果在客户端断开连接期间被创建了,并且随后在客户端连接上之前又删除了,这种情况下,这个watch事件可能会被丢失。
Kafka Kafka 各个名词概述 Topic
Broker
Partition
Producer
Consumer
Leader Replica
Follower Replica
Rebalance
Consumer Offset
Consumer Group
Cordinator
Cotroller
Interceptor
Record Kafka 处理的主要对象。
Topic 主题是承载消息的逻辑容器,在实际使用中多用来区分具体的业务。
Producer 向主题发布消息的客户端应用程序。
Consumer 订阅这些主题消息的客户端应用程序就被称为消费者。
Consumer Group 指的是多个消费者实例共同组成一个组来消费一个主题。该组主题中的每个分区都只会被组内的一个消费者实例消费,其他消费者实例不能消费它。消费者组提升了消费者端的吞吐量。
Broker 一个 Kafka 集群由一个至多个 Broker 组成,Broker 负责接收和处理客户端发送过来的请求,以及对消息进行持久化。
Replication 备份机制
Leader Replica 领导者副本,对外提供服务。
Follower Replica 追随者副本,不对外提供服务,不能与外界进行交互。对 Leader 副本同步有延迟。
Cordinator 协调者
Controller 控制器 Partition 比如 MongoDB 和 Elasticsearch 中的 Sharding、HBase 中的 Region,其实它们都是相同的原理,只是 Partitioning 是最标准的名称。
生产者生产的每条消息只会被发送到一个分区中,也就是说如果向一个双分区的主题发送一条消息,这条消息要么在分区 0 中,要么在分区 1 中。如你所见,Kafka 的分区编号是从 0 开始的,如果 Topic 有 100 个分区,那么它们的分区号就是从 0 到 99。
一个有序不变的消息队列,每个主题下可以有多个分区。
副本和分区的关系 副本是在分区这个层级定义的,每个分区下可以配置若干个副本,其中只能有一个领导者副本和 N-1 个追随者副本。生产者向分区写入消息,每条消息在分区中的位置信息有Offset 的数据来表征。分区的位移总是从 0 开始。
Rebalance 消费者组里面的所有消费者实例不仅“瓜分”订阅主题的数据,它们还能彼此协助,假如组内的某个实例挂掉了,Kafka 能够自动检测到,然后把这个 Faild 实例之前负责的分区转移给其他或者消费者。这就是 Rebalance,这个有很多 Bug。
Consumer Offset 每个消费者在消费消息的过程中必然需要有个字段记录它当前消费到了分区的哪个位置上。
Broker注册 Broker是分布式部署并且相互之间相互独立,但是需要有一个注册系统能够将整个集群中的 Broker 管理起来 ,此时就使用到了Zookeeper。在 Zookeeper 上会有一个专门用来进行Broker服务器列表记录 的节点:
/brokers/ids
每个Broker在启动时,都会到Zookeeper上进行注册,即到/brokers/ids下创建属于自己的节点,如/brokers/ids/[0…N]。
Kafka使用了全局唯一的数字来指代每个Broker服务器,不同的Broker必须使用不同的Broker ID进行注册,创建完节点后,每个Broker就会将自己的IP地址和端口信息记录 到该节点中去。其中,Broker创建的节点类型是临时节点,一旦Broker宕机,则对应的临时节点也会被自动删除。
Kafka ACK 机制 1 leader
0 不管
-1 所有
Kafka Zero Copy 和大家的零拷贝技术一样,少了用户态的参与。
Kafka 副本机制 只有 Leader 副本才供外界读写,Follower 副本只是作为冗余,怕 Leader 副本 down 掉数据全部丢失。
Kafka 跨机房同步数据 Kafka 消息压缩 Kafka 默认不使用压缩,合理使用压缩,可以减少带宽使用。
GZIP、Snappy 、LZ4、Zstandard 算法(简写为 zstd)
在 Producer 端和 Broker 端设置相同(或者 Broker 端不改 compression.type 参数,默认为 producer 端的压缩方法)。
在吞吐量方面:LZ4 > Snappy > zstd 和 GZIP;
而在压缩比方面,zstd > LZ4 > GZIP > Snappy。
Kafka 高水位 高水位的作用在 Kafka 中,高水位的作用主要有 2 个。
定义消息可见性,即用来标识分区下的哪些消息是可以被消费者消费的。
帮助 Kafka 完成副本同步。
它依靠一个名为 LSO(Log Stable Offset)的位移值来判断事务型消费者的可见性。
与 Leader 副本保持同步。判断的条件有两个。
该远程 Follower 副本在 ISR 中。
该远程 Follower 副本 LEO 值落后于 Leader 副本 LEO 值的时间,不超过 Broker 端参数 replica.lag.time.max.ms 的值。如果使用默认值的话,就是不超过 10 秒。
Leader Epoch
Epoch。一个单调增加的版本号。每当副本领导权发生变更时,都会增加该版本号。小版本号的 Leader 被认为是过期 Leader,不能再行使 Leader 权力。
起始位移(Start Offset)。Leader 副本在该 Epoch 值上写入的首条消息的位移。
为什么 Kafka 的 Consumer 采用 pull 方式,Provider 采用 push 方式 消费者消费消息是需要一定时间的,为了防止推送过多消息给 Consumer 端,导致 Consumer 挂掉,让 Consumer 按需来自己 pull 消息。
Lucene Lucene全文搜索的原理 https://blog.csdn.net/yangqian201175/article/details/51462413
《Lucene in action》
ELK Elasticsearch 简介 primary shard, replica shard,cordinating
Elasticsearch 聚合操作 Aggregation
Elasticsearch DLS Query TermLevel
Elasticsearch 查询 支持多种类型查询,返回对应 score
Logstash docker pull docker.elastic.co/logstash/logstash:7.1.0
Kibana 中文环境设置 I18N_LOCALE=zh-CN
BigData HDFS Hadoop 分布式文件系统。NameNode + DataNode,NameNode 只存 metadata,实际文件存在各个 DataNode。
是的,它只是个文件系统,虽然一切皆文件。
MapReduce MapReduce 是一种处理海量数据的并行编程模型和计算框架,用于对大规模数据集进行并行计算。
MapReduce 一个任务的运行需要由 JobTracker 和 TaskTracker 两类空志节点的配合来完成,JobTracker 将 Mappers 和 Reducers 分配给空闲的 TaskTracker 后,有TaskTracker 来执行这些任务。MapReduce 框架尽量在那些存储数据的节点(如 DataNode)上来执行计算任务,采用移动计算而非移动数据的思想,减少数据在网络中传输,以此来提高计算效率。同时 JobTracker 也负责任务的容错管理,如果某个 TaskTracker 发生故障,JobTracker 会重新进行任务调度。
Hive 将 SQL 解释成 MapReduce 任务。
Hive是早期将高级查询语言SQL引入Hadoop 平台的引擎之一,早期的Hive服务器进程被称作Hiveserver1;Hiveserver1既不支持处理并行的多个连接,又不支持访问授权控制;后来这两个问题在Hiveserver2上被解决,Hiveserver2能够使用grant/revoke语句来限制用户对数据库、表、视图的访问权限,行列权限的控制是通过生成视图来实现的;但Hiveserver2的授权管理体系被认为存在问题,那就是任何通过认证登陆的用户都能够为自己增加对任何资源的访问权限。也就是说Hiveserver2提供的不是一种安全的授权体系,Hiveserver2的授权体系是为防止正常用户误操作而提供保障机制;不是为保护敏感数据的安全性而设计的。然而这些更多的是某些公司的说辞,事实上Hiveserver2自身的安全体系也在逐步完善,上述问题也在快速修复中。
连接 从 Hive 连接中可以看出用的是 Hiveserver2
beeline -u jdbc:hive2://olap1:10000/ –maxWidth=1000
数据仓库 从 WEB 开发到离线数仓,一个用多中间件 CRUD 开发,到另一个用 SQL 开发。换个地方 CRUD 而已
UDF,UDAF,UDTF。脱敏函数(UDF),聚合函数(UDAF 自定义count,sum),UDTF
UDF 一进一出,实现 UDF 接口,编写evaluate 方法,例如可用作脱敏函数,对数据进行脱敏。
1 2 3 4 5 class SimpleUDFExample extends UDF public Text evaluate (Text input) return new Text("Hello " + input.toString()); } }
UDAF 多进一出,实现 AbstractGenericUDAFResolver,可用作实现自定义聚合函数。下面是求两个列的线性方程的相关系数。
看另一篇文章。
HBase HBase是一个高可靠、高性能、面向列、可伸缩的分布式数据库,是谷歌 BigTable 的开源实现,主要用来存储非结构化和半结构化的松散数据,运行在 HDFS 之上。设计 RowKey 尽量将数据均地分布在各个 Region 上,并且 RowKey 为等长 ,用于拼接 RowKey 的列必须是确定长度的值,高频词往前提,同样查询频率的,辨识度高,更短的列往前提。等长是因为桶排序。
没有特殊要求,一个列族就可以满足大部分要求 ,多个列族会影响性能,实际生产中,都是一个列族,多个列族会有问题,具体的看《HBase 原理与实战》这本书。
拼接 Rowkey 是按照特定需求来做的,不能乱拼。
HyperBase 星环增强了 HBase 变成了 HyperBase。查询更方便,千亿数据,查询秒返回。支持普通单表查询,多表查询慢,聚合操作更慢。聚合操作使用以下部件实现。支持更为丰富的值类型,例如 JSON 存储。
不过还是只是支持 PB 级别数据罢了,再大就不太行了。
Kylin 聚合操作。
Spark Spark SQL 也可以将 SQL 转换成 MR 任务,星环的 Inceptor 就整合了 Spark。Hive-on-spark,将 Hive 的 MR 任务转换成 Spark 的 job。
Flink 流式处理中间件。还是写 SQL。
符合事件驱动架构设计。
Kafka Streaming 也可以,但前者大公司都在用。做个 CRUD boy 他不香吗?
CDH TDH Cloudera Data Hub,Transwarp Data Hub 一站式大数据平台
Transwarp Data Hub 对标的国外的 CDH,其实也用到了 CDH 开源的代码,我看到安装包里面有 CDH 的东西,并且他们封装的 Elasticsearch Transport 的 SDK,打包有问题。
OLAP Online analytical processing 联机分析处理
OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
OLAP由三个基本的分析操作组成:上卷(roll-up)、钻取(drill-down)、切片(slicing)和切块(dicing)。上卷涉及可以在一个或多个维度中累积和计算的数据的聚合。例如,所有的销售办事处汇总到销售部门,以预测销售趋势。相比之下,钻取是一种允许用户浏览详细信息的技术。例如,用户可以查看组成一个地区销售额的单个产品的销售额。切片和切块是说,用户可以从OLAP多维数据集中取出(切片)一组特定的数据,并从不同的角度查看(切块)切片
https://zh.wikipedia.org/wiki/%E7%B7%9A%E4%B8%8A%E5%88%86%E6%9E%90%E8%99%95%E7%90%86
OLTP 联机事务处理 (OLTP , Online transaction processing)是指透过信息系统 、电脑网络 及数据库 ,以在线交易的方式处理一般即时性的作业资料,和更早期传统数据库系统大量批量的作业方式并不相同。OLTP通常被运用于自动化的资料处理工作,如订单输入、金融 业务…等反复性的日常性交易活动。 和其相对的是属于决策分析层次的联机分析处理 (OLAP)。
来自
J2EE 规范 JMS 下面的来自oracle 官方文档
《大型分布式网站架构·设计与实践》中只是一笔带过一些概念,没有 JMS 实际代码,然后用 ActiveMQ & JMS 的标题。
定义 Java Message Service 是一组 Java 应用程序接口,它提供消息的创建、发送、接收、读取等一系列的服务。
原文
The Java Message Service is a Java API that allows applications to create‚ send‚ receive‚ and read messages
JMS 定义了一组公共应用程序接口和相应的语法,是一种通用的 API。
原文
the JMS API defines a common set of interfaces and associated semantics that allow programs written in the Java programming language to communicate with other messaging implementations
它定义了五种消息类型,如下。
原文
The JMS API defines five message body formats‚ also called message types‚ which allow you to send and receive data in many different forms and which provide compatibility with existing messaging formats.
Message Type
Body Contains
TextMessageA java.lang.String object (for example, the contents of an XML file).
MapMessageA set of name-value pairs, with names as String objects and values as primitive types in the Java programming language. The entries can be accessed sequentially by enumerator or randomly by name. The order of the entries is undefined.
BytesMessageA stream of uninterpreted bytes. This message type is for literally encoding a body to match an existing message format.
StreamMessageA stream of primitive values in the Java programming language, filled and read sequentially.
ObjectMessageA Serializable object in the Java programming language.
MessageNothing. Composed of header fields and properties only. This message type is useful when a message body is not required.
JDBC 1.0 规范
2.0 规范 数据源
DataSource 这个接口是在JDBC 2.0规范可选包中引入的API。它比DriverManager更受欢迎,因为它提供了更多底层数据源相关的细节,而且对应用来说,不需要关注JDBC驱动的实现。JDBC API中只提供了DataSource接口,没有提供DataSource的具体实现,DataSource具体的实现由JDBC驱动程序提供。主流的数据库连接池也提供了其实现,如 Druid,c3p0,Hikaricp
CommonDataSource
连接池相关
ConectionPoolDataSource 支持缓存和复用Connection对象,这样能够在很大程度上提升应用性能和伸缩性。
PooledConnection
ConnectionEvent
ConnectionEventListener
ResultSet 扩展
RowSet 继承自java.sql包下的ResultSet接口,相较于java.sql.ResultSet而言,RowSet的离线操作能够有效地利用计算机越来越充足的内存减轻数据库服务器的负担。由于数据操作都是在内存中进行的,然后批量提交到数据源,因此灵活性和性能都有了很大的提高。RowSet默认是一个可滚动、可更新、可序列化的结果集,而且它作为一个JavaBean组件,可以方便地在网络间传输,用于两端的数据同步。通俗来讲,RowSet就相当于数据库表数据在应用程序内存中的映射,我们所有的操作都可以直接与RowSet对象交互。RowSet与数据库之间的数据同步,作为开发人员不需要关注。
RowSetEvent
RowSetInternal
RowSetListener
RowSetMetaData
RowSetReader
RowSetWriter
分布式扩展
XAConnection
XADataSource 该实例返回的Connection对象能够支持分布式事务。
上面三个都是接口。
需要掌握的 API java.sql.Wrapper
java.sql.Connection
java.sql.Statement
java.sql.PrepareStatement
java.sql.CallableStatement
java.sql.DatabaseMetaData
java.sql.ParameterMetaData
java.sql.ResultSet
java.sql.ResultSetMetaData
这些接口都继承了java.sql.Wrapper接口,里面有两个方法
1 2 3 4 5 6 7 8 <T> T unwrap (java.lang.Class<T> iface) throws java.sql.SQLException ; boolean isWrapperFor (java.lang.Class<?> iface) throws java.sql.SQLException
JNDI JNDI(Java Naming and Directory Interface,Java命名和目录接口)为应用程序提供了一种通过网络访问远程服务的方式。
RMI Servlet servlet-class
JTA(Java Transaction Architecture) JTA定义了一种标准的API,应用系统由此可以访问各种事务监控。
JTS(Java Transaction Service) 参考 https://www.ibm.com/developerworks/cn/java/j2ee/
Cloud Native 云原生 云原生十二要素 十二要素程序的核心思想
使用声明 的方式来搭建自动化环境,最大限度地减少新加入项目的开发人员的时间和成本。
与底层操作系统之间建立清晰的约定,在执行环境之间提供最大的可移植性 。
适合部署 在现代的云平台上 ,无须提供服务器和系统管理工具。
最大程度减少 开发环境与生产环境之间的区别 ,通过持续部署 获得最大的灵活性。可以在不对工具、架构或开发实践带来重大变动的前提下,进行水平扩展 。
十二要素程序的实践
代码库
一份版本控制下的基准代码库,多份部署
依赖
显示声明和隔离依赖关系
配置
在环境中存储配置
后端服务
把后端服务当作附加资源
构建、发布、运行
严格分离构建和运行阶段
进程
将应用程序作为一个或多个无状态进程执行
端口绑定
通过端口绑定暴露服务
并发
通过进程模型进行扩展
易处理
通过快速启动和正常关机来最大限度地提高健壮性
开发/生产环境一致
尽可能保持开发、预发布和生产环境的配置一致
日志
将日志视为事件流
管理进程
将管理任务作为一次性进程运行
Cloud Foundry Pivotal 团队 12 年发布的云原生平台,完美实现了云原生的十二要素。Cloud Foundry 创始人之一,Chris Richardson,也是 《微服务架构设计模式》的作者。你想要了解微服务,这本书大量图解,帮你了解。
Amazon S3 容器化 Docker 构建 Dockerfile,参考我的 evaluation 库
1 2 3 4 5 6 7 docker build docker run docekr ps docker kill docker compose up docker images docker rm
Kubernetes (K8s,K3s) 简介 Kubernetes 是一个可移植的、可扩展的开源平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化。
K3s 国产的轻量级的 K8s。用树莓派搭建 K3s
Kubernetes 是一个 Docker 编排框架。Docker 编排框架将运行 Docker 的一组计算机视为资源池。你只需要告诉 Docker 编排框架运行你的服务的 N 个实例,它就会自动把其余的事情搞定。
有三个主要功能:
资源管理:将一组计算机视为由 CPU、内存和存储卷构成的资源池,将计算机集群视为一台计算机。
调度:选择要运行容器的机器。默认情况下,调度考虑容器的资源需要和每个节点的可用资源。它还可以实现在同一节点上部署具有亲和性(affinity)的容器,或确保特定的几个容器分散部署在不同的节点之上(反亲和性,anti-affinity)
服务管理:实现命名和版本化服务的概念,这个概念可以直接映射到微服务架构中的具体服务。编排框架确保始终运行所需数量的正常实例。它实现请求的负载均衡。编排框架也可以执行服务的滚动升级,并允许你会滚到旧版本。
Kubenetes 的架构 Kubernetes 在一组机器上运行。下图显示了 Kubernetes 集群的架构。Kubernetes 集群中的计算机角色分为主节点和普通节点(也称为节点)集群通常只有很少的几个主节点(可能只有一个)和很多普通节点。主节点负责管理集群。Kubernetes 的普通节点称为 “工作节点”,它会运行一个或多个 Pod。Pod 是 Kubernetes 的部署单元,由一组容器组成。
API 服务器:用于部署和管理服务的 REST API,例如,可被 kubectl 命令行使用。
Etcd:存储集群数据键值的 NoSQL 数据库。
调度器:选择要运行的 Pod 的节点。
控制器管理器:运行控制器,确保集群状态与预期状态匹配。例如,一种被称为复制(replication)控制器的控制通过启动和终止实例来确保运行所需数量的服务实例。
Kubenetes 集群由管理集群的主节点和运行服务的普通节点组成。开发人员和部署流水线通过 API 服务器与 Kubernetes 交互,API 服务器与主节点上运行的其他集群管理软件一起运行。应用程序容器在节点上运行,每个节点运行一个 Kubelet (它管理应用程序容器),以及一个 Kube-proxy (它将应用程序请求路由到 Pod),可以直接使用代理,也可以通过配置 Linux 内核中内置的 iptable 路由规则间接地完成路由工作。
普通节点运行多个组件,包括以下内容:
Kubelet : 创建和管理节点上运行的 Pod。
Kube-proxy:管理网络,包括跨 pod 的负载均衡。
Pods:应用程序服务。
Kubernetes 的关键概念
Pod:Pod 的 Kubernetes 的基本部署单元。它由一个或多个共享 IP 地址和存储卷的容器组成。服务实例的 pod 通常由单个容器组成,例如运行 JVM 的容器。但在某些情况下,Pod 包含一个或多个实现支持功能的边车(sidecar)容器。例如,Nginx 服务器可以有一个边车容器,定期执行 git pull 以下载最新版本的网站。Pod 的生命周期很短,因为 Pod 的容器或它运行的节点可能会崩溃。
Deployment:Pod 的声明规范。Deployment 是一个控制器,可确保始终运行所需数量的 Pod 实例(服务实例)。它通过滚动升级和会滚来支持版本控制。每个服务都是 Kubernetes 的一个 Deployment。
Servcie:向应用程序服务的客户端提供的一个静态/稳定的网络地址。它是基础设施提供的服务发现一种形式。每个 Service 具有一个 IP 地址和一个可解析位该 IP 地址的 DNS 名称,并跨一个或多个 Pod 对 TCP 和 UDP 流量进行负载均衡处理。IP 地址和 DNS 名称只能在 Kubernetes 内部访问。也可以配置可从集群外部访问的服务。
ConfigMap:名称与值对的命名集合,用于定义一个或多个应用程序服务的外部化配置。Pod 容器的定义可以饮用 ConfigMap 来定义容器的环境变量。它还可以使用 ConfigMap 在容器内创建配置文件。可以使用 Secret 来存储敏感信息(如密码),它也是 ConfigMap 的一种形式。
在 Kubernetes 上部署 Restaurant Service 定义一个部署(Deployment)对象。最简单的方法是编写 YAML 文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 apiVersion: extensions/v1beta1 kind: Deployment metadata: name: ftgo-restaurant-service spec: replicas: 2 template: metadata: labels: app: ftgo-restaurant-service spec: containers: - name: ftgo-restaurant-service image: msapatterns/ftgo-restaurant-service:lastes imagePullPolicy: Always ports: - containerPort: 8080 nanme: httpport env: - name: JAVA_OPTS value: "-Dsun.net.inetaddr.ttl=30" - name: SPRING_DATASOURCE_URL value: jdbc:mysql://ftgo-mysql/eventuate - name: SPRING_DATASOURCE_USERNAME valueFrom: secretKeyRef: name: ftgo-db-secret key: username - name: SPRING_DATASOURCE_PASSWORD valueFrom: secretKeyRef: name: ftgo-db-secret key: password - name: SPRING_DATASOURCE_DRIVER_CLASS_NAME value: com.mysql.jdbc.Driver - name: EVENTUATELOCAL_KAFKA_BOOTSTRAP_SERVERS value: ftgo-kafka:9092 - name: EVENTUATELOCAL_KAFKA_ZOOKEEPER_CONNECTION_STRING value: ftgo-zookeeper:2181 livenessProbe: httpGet: path: /actuator/health port: 8080 initialDelySeconds: 60 periodSeconds: 20 readinessProbe: httpGet: path: /actuator/health port: 8080 initialDelaySeconds: 60 periodSeconds: 20
接下来是部署 Service(这里的服务发现组件),K8s 自带的。
部署 API Gateway。大同小异,同上。
Kubernetes 零停机部署
构建新的容器镜像,变更版本
编辑服务部署的 YAML 文件,以便它引用新镜像。
使用 kubectl apply -f 命令更新部署。
K8s 将对 Pod 进行滚动升级。
1 kubectl rollout undo deployment ftgo-restaurant-service
简介 FaaS、SaaS、PasS、IaaS、Serverless 这些内容都是一些概念,并不是实际的实现,尤其是 Serverless 截止 2021 年初还没有标准的规范,我 Amazon 可以说我 Lambda 是标准的,我 Spring Boot + Azure 也可以说是 Serverless,我 Serverless X 也可以说是这个。某一次的技术沙龙直播,我问这个腾讯相关的人员,说各有优缺点。
下面的图层描绘了不同抽象层次上的云服务类型。
Function as Service 功能即服务是一类云计算服务,它提供了一个平台,允许客户开发,运行和管理应用程序功能,而无需构建和维护通常与开发和启动应用程序相关的基础结构的复杂性。按照此模型构建应用程序是实现“无服务器”体系结构的一种方法,通常在构建微服务应用程序时使用。
Function as a service (FaaS ) is a category of cloud computing services that provides a platform allowing customers to develop, run, and manage application functionalities without the complexity of building and maintaining the infrastructure typically associated with developing and launching an app.[1] Building an application following this model is one way of achieving a “serverless “ architecture, and is typically used when building microservices applications.
Software as a Service 软件即服务 Software as a Service,亦可称为“按需即用软件”(即“一经要求,即可使用”)软件即服务,它是一种软件 交付模式。在这种交付模式中,软件仅需通过网络,不须经过传统的安装步骤即可使用,软件及其相关的数据 集中托管 于云端 服务。用户通常使用精简客户端 ,一般即经由网页浏览器 来访问、访问软件即服务。SaaS 最大的特色在于软件本身并没有被下载到用户的硬盘,而是存储在提供商的云端或者服务器。对比传统软件需要花钱购买,下载。软件即服务只需要用户租用软件,在线使用,不但大大减少了用户购买风险, 也无需下载软件本身,无设备要求的限制。
平台即服务 ,是一种云计算 服务,提供运算平台与解决方案服务。在云计算的典型层级中,PaaS层介于软件即服务 与基础设施即服务 之间。
PaaS提供用户将云端基础设施部署与创建至客户端,或者借此获得使用编程语言 、程序库 与服务。用户不需要管理与控制云端基础设施(包含网络、服务器、操作系统或存储),但需要控制上层的应用程序部署与应用托管的环境。[1]
PaaS 将软件研发的平台做为一种服务,以软件即服务 (SaaS)模式交付给用户。因此,PaaS也是SaaS模式的一种应用。但是,PaaS的出现可以加快SaaS的发展,尤其是加快SaaS应用的开发速度。
PaaS 提供软件部署平台(runtime),抽象掉了硬件和操作系统细节,可以无缝地扩展(scaling)。开发者只需要关注自己的业务逻辑,不需要关注底层。下面这些都属于 PaaS。
K8s + Docker 也就相当于 PaaS 的实现。
Infrastructure as a Service 基础设施为服务。
云原生开发最终演化方向。
Serverless 无服务化,冷启动应用,按需分配服务,适合边缘业务。
下下一代项目架构,目前只是 AWS 提供了 Lambda 来实现,在英文版的 InfoQ 上,有人把 Spring Boot + Azure = Serverless。
其实还没有非常明确的定义 Serverless 的规范,任何厂商都可以说他们的才是正统的 Serverless 服务器。
SPI SPI(Service Provider Interface)是 JDK 内置的一种服务提供发现机制。SPI 是一种动态替换发现的机制。 SPI 典型的实现为 JDBC。
DDD DDD 名词解释
子域
核心域
通用域
支撑域
限界上下文
聚合
聚合根
实体
值对象
领域事件
依赖倒置
仓储(Repository)
ServiceManager
DDD 如何落地 划分子域,子域内构建事件风暴。
DDD 包名规范 infrastructure
repository
service
entity
OS 动态内存分配 空闲列表 可用表格,可用链表存储。
分区分配算法
分区释放算法 指针碰撞