电子原版目录以及概要
请购买实体书籍,支持作者、翻译以及出版社
Creating and Destroying Objects 用静态工厂方法代替构造器 1 2 3 public static Boolean valueOf (boolean b) return b ? Boolean.TRUE : Boolean.FALSE; }
静态工厂方法与设计模式中的工厂方法模式不同。并不能直接对应设计模式的工厂方法。
优势
有名字(像这种BigInteger.probablePrime(int bitLength,Random rnd))
不必每次调用他们的时候,都创建一个新对象。像Integer.MAX_VALUE = 0x7fffffff(享元Flyweight模式)真正的享元模式如下,Integer中有个私有静态类,叫IntergeCache
可以返回原返回类型的任何子类型的对象。Java8允许接口中含有静态方法,Java9允许接口中有私有的静态方法,但是静态域和静态成员变量仍然需要是公有的。
所返回的对象的类可以随着每次调用而发生变化,这取决于静态工厂方法的参数值。
方法返回的对象所属的类,在便携包含该静态工厂方法的类时可以不存在。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 public static Integer valueOf (int i) if (i >= IntegerCache.low && i <= IntegerCache.high) return IntegerCache.cache[i + (-IntegerCache.low)]; return new Integer(i); } private static class IntegerCache static final int low = -128 ; static final int high; static final Integer cache[]; static { int h = 127 ; String integerCacheHighPropValue = sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high" ); if (integerCacheHighPropValue != null ) { try { int i = parseInt(integerCacheHighPropValue); i = Math.max(i, 127 ); h = Math.min(i, Integer.MAX_VALUE - (-low) -1 ); } catch ( NumberFormatException nfe) { } } high = h; cache = new Integer[(high - low) + 1 ]; int j = low; for (int k = 0 ; k < cache.length; k++) cache[k] = new Integer(j++); assert IntegerCache.high >= 127 ; } private IntegerCache () }
缺点
类如果不含公有或者受保护的构造器,就不能被子类化
难发现它们
BeanDefinitionBuiler 就是将静态工厂方法 和 构建器 模式结合的案例。
遇到多个构造器参数时要考虑使用构建器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 public final class BeanDefinitionBuilder private final AbstractBeanDefinition beanDefinition; private int constructorArgIndex; public static BeanDefinitionBuilder genericBeanDefinition (String beanClassName) BeanDefinitionBuilder builder = new BeanDefinitionBuilder(new GenericBeanDefinition()); builder.beanDefinition.setBeanClassName(beanClassName); return builder; } public BeanDefinitionBuilder setInitMethodName (@Nullable String methodName) this .beanDefinition.setInitMethodName(methodName); return this ; } public BeanDefinitionBuilder setDestroyMethodName (@Nullable String methodName) this .beanDefinition.setDestroyMethodName(methodName); return this ; } public BeanDefinitionBuilder setScope (@Nullable String scope) this .beanDefinition.setScope(scope); return this ; } public AbstractBeanDefinition getBeanDefinition () this .beanDefinition.validate(); return this .beanDefinition; } } public class BeanDefinitionAPI public GenericBeanDefinition getGeneriBeanDefinition () return (GenericBeanDefinition)BeanDefinitionBuilder .genericBeanDefinition("org.springframework.web.client.RestTemplate" ) .setScope("singleton" ) .getBeanDefinition(); } }
如果类的构造器或者静态工厂中具有多个参数,设计这种类时,Builder模式就是一种不错的选择
用私有构造器或者枚举类型强化Singleton属性 如果要阻止反射实例化单例类,可以在被要求创建第二个实例的时候,抛出异常。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class Singleton private volatile Singleton singleton = null ; private Singleton () if (singleton != null ){ throw new IllegalAccessException(); } } public static getInstance () if (singleton == null ){ synchronized (Singleton.class ) { if (singleton == null ){ singleton = new Singleton(); } } } return singleton; } }
单元素的枚举类型经常成为实现Singleton的最佳方法。当然如果Singleton必须扩展一个超类,而不是扩展Enum的时候,则不宜使用这个方法。
下面是 Spring Boot 2.0 引入的单例类。具体执行顺序如下
SpringApplication#run --> SpringApplication#prepareEnvironment --> SpringApplication#configureEnvironment --> ApplicationConversionService#getSharedInstance
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 public class ApplicationConversionService extends FormattingConversionService private static volatile ApplicationConversionService sharedInstance; public ApplicationConversionService () this (null ); } public ApplicationConversionService (StringValueResolver embeddedValueResolver) if (embeddedValueResolver != null ) { setEmbeddedValueResolver(embeddedValueResolver); } configure(this ); } public static ConversionService getSharedInstance () ApplicationConversionService sharedInstance = ApplicationConversionService.sharedInstance; if (sharedInstance == null ) { synchronized (ApplicationConversionService.class ) { sharedInstance = ApplicationConversionService.sharedInstance; if (sharedInstance == null ) { sharedInstance = new ApplicationConversionService(); ApplicationConversionService.sharedInstance = sharedInstance; } } } return sharedInstance; } }
通过私有构造器强化不可实例化的能力 像这种工具类就私有构造器。使用 final 防止继承,使用私有构造器防止实例化(开安全后防止反射实例化)。
1 2 3 4 5 public final class DateUtil private DateUtil () }
例如 spring.core 中的 String 工具类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public abstract class StringUtils private static final String FOLDER_SEPARATOR = "/" ; private static final String WINDOWS_FOLDER_SEPARATOR = "\\" ; private static final String TOP_PATH = ".." ; private static final String CURRENT_PATH = "." ; private static final char EXTENSION_SEPARATOR = '.' ; public StringUtils () } }
优先考虑依赖注入来引用资源 通过依赖注入而非手动 new 对象,降低类于类之间的耦合度。而且应该尽量是基于接口而非实现来注入,这样更适合* 经常变更的类*,或者模块 。当然,不是 Service 都需要写接口,除非你真的很需要,例如 SOA 程序、微服务程序,需要提供给外部 SDK。像 Spring Cloud 所有模块,以及 Spring 所定义的所有抽象一样,定义了统一的接口,引用的都是接口,而非实现类,Spring 统一的 Caching 等接口也是如此。
静态工具类和Singleton类不适合于需要引用底层资源的类。
关于解耦,右侧有更多解释。细数软件架构中的解耦
集中化配置,根据服务动态解析 IP 也算是解耦的方式。
当创建一个新的实例时,就将该资源传到构造器中
依赖注入(Dependency Injection)
类似的内容,在进程间的 Broker 消息模式也有体现。
关于构造器注入好,还是 Setter 注入好,个人认为是前者好。Spring作者也推荐前者,因为这样能判断你是不是传了非空、非法的参数。
如果想更深入了解如何实现循环依赖,在构造器注入如何实现,可以看看 ObjectProvider,以及 Spring Boot MyBatis 的内容,那个比较简单。
Spring 中单例的对象,并不一定是全局唯一的,它是 每个ClassLoader 中唯一的,static 对象也是。所以插件 Spring Dev Tool 让项目重启,只需要新的 ClassLoader 加载这些内容。这里有个小知识点,就是分级处理。和 JVM 的分代处理其实是差不多的,就是将部分不变的类用固定的 ClassLoader 加载,项目中可变的类用新的 ClassLoader 加载,这样就实现每次代码变更,不用全部重新加载的功能了。当然,这里是简化了实现细节,内部实现没有这么简单。
避免创建不必要的对象
字符串循环累加
包装类型循环累加
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 String s = new String("bikini" ); String s = "bikini" ; static boolean isRomanNumeral (String s) return s.matche("^(?=.)M{1,3}?(CM|C?D|D?C{1,3})?(XC|XL|L|L?X{1,3})?(IX|I?V|V?I{1,3})?$" ); } public class RomanNumerals private static final Pattern ROMAN = Pattern.compile("^(?=.)M{1,3}?(CM|C?D|D?C{1,3})?(XC|XL|L|L?X{1,3})?(IX|I?V|V?I{1,3})?$" ); static boolean isRomanNumeral (String s) return ROMAN.matcher(s).matches(); } }
适配器是指这样一个对象:它把功能委托给一个后备的对象(backing object),从而为后备对象提供一个可以代替的接口。
WebMvcConfigurerAdapter这是个适配器,一般用于配置web的一些配置,如拦截器Interceptor,JSONformatter等,不过在Java8出来接口中声明 default 方法后,这个类就被声明 @Deprecated。
优先使用基础类型而不是装箱基本类型,要当心无意识的自动装箱 。(当然,实际生产中,除非你用于科学计算,一般都用包装类,例如 long 和 Long,小写的 l 容易看成大写 i 避免歧义)。
1 2 3 4 5 6 7 8 9 private static long sum () Long sum = 0L ; for (long i = 0 ;i <= Integer.MAX_VALUE; i++){ sum += i; } return sum; }
1 2 3 4 5 6 7 8 9 10 11 12 13 public class Stack public Object pop () if (size ==0 ){ return new NullPointException(); } Object result = elements[--size]; elements[size] = null ; return result; } }
内存泄漏的另一个常见来源是缓存。用WeakHashMap代表缓存。只有当所要的缓存项的生命周期是由该键的外部引用而不是由值决定时,WeakHashMap才有用处。
第三个常见来源是监听器和其他回调。可以借助 Heap 剖析工具(Heap Profiler)发现内存泄漏问题。
ThreadLocal 是否存在内存泄漏问题,为什么?
阿里云云栖号
避免使用finalizer方法,和Java9的cleaner方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class Room implements AutoCloseable private static final Clearner cleaner = Cleaner.create(); private final State state; private final Cleaner.Cleanable cleanable; private static class State implements Runnable int numJunkPiles; State(int numJunkPiles){ this .numJunkPiles = numJunkPiles; } @Override public void run () System.out.println("Cleaning room" ); numJunkPiles = 0 ; } } public Room (int numJunkPiles) state = new State(numJunkPiles); cleanable = cleaner.register(this ,state); } @Override public void close () cleanable.clean(); } }
try with resources 优先于 try finally 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 static String firstLineOfFile (String path,String defualtVal) try (BufferedReader br = new BufferedReader(new FileReader(path))){ return br.readLine(); }catch (IOException e){ return defaultVal; } } void query () Connection conn = null ; PreparedStatement pst = null ; ResultSet rs = null ; try { conn = DriverManager.getConnection("com.mysql.jdbc.Driver" ); pst = conn.prepareStatement("SELECT 1 FROM dual" ); pst.execute(); rs = pst.getResultSet(); rs.getInt(0 ); }catch (Exception e){ e.printStackTrace(); }finally { try { if (conn != null ){ conn.close(); } }catch (Exception e){ e.printStackTrace(); } try { if (pst != null ){ pst.close(); } }catch (Exception e){ e.printStackTrace(); } try { if (rs != null ){ rs.close(); } }catch (Exception e){ logger.error(getStackTraceAsString(e)); } } } private String getStackTraceAsString (Throwable e) if (e == null ){ return "" ; } StringWriter stringWriter = new StringWriter(); e.printStackTrace(new PrintWriter(stringWriter)); return stringWriter.toString(); }
Methods Common to All Objects 什么时候应该覆盖equals方法? 如果类具有自己特有的“逻辑相等”(logical equality)概念,而且超类还没有equals。这通常属于”值类“(Value class),值类仅仅是表示一个表示值的类,例如Integer或String。
1 2 3 4 5 String foo = new String("str" ); String bar = new String("str" ); foo.equals(bar); foo == bar ;
equals方法实现了等价关系(equivalence relation)
放心,在《算法》Java 版本的这本书上也有介绍,这只是个基本的概念而已。
– 所有前提是 对于任何非null的引用值x
自反性(reflexive):x.equals(x)必须为true
对称性(symmetric):如果x.equals(y)==true,必定y.equals(x);前提是两个非null
传递性(transitive):x.equals(y)==true,y.equals(z)==true,z.equals(x)==true;
一致性(consistent):当x.equals(y)==true时,只要在比较操作在对象中所用的信息没有被修改,多次调用,都是true。
任何非null的引用值x,x.equals(null)==true;
里氏替换原则(Liskov substitution principle)认为,一个类型的任何重要属性也将适用于它的子类型,因此为该类型编写的任何方法,在它的子类型上也应该同样运行得很好。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 @AutoValue public abstract class AutoValueMoney public abstract String getCurrency () public abstract long getAmount () public static AutoValueMoney create (String currency, long amount) return new AutoValue_AutoValueMoney(currency, amount); } } public final class AutoValue_AutoValueMoney extends AutoValueMoney private final String currency; private final long amount; AutoValue_AutoValueMoney(String currency, long amount) { if (currency == null ) throw new NullPointerException(currency); this .currency = currency; this .amount = amount; } @Override public int hashCode () int h = 1 ; h *= 1000003 ; h ^= currency.hashCode(); h *= 1000003 ; h ^= amount; return h; } @Override public boolean equals (Object o) if (o == this ) { return true ; } if (o instanceof AutoValueMoney) { AutoValueMoney that = (AutoValueMoney) o; return (this .currency.equals(that.getCurrency())) && (this .amount == that.getAmount()); } return false ; } } @Test public void givenValueTypeWithAutoValue_whenFieldsCorrectlySet_thenCorrect () AutoValueMoney m = AutoValueMoney.create("USD" , 10000 ); assertEquals(m.getAmount(), 10000 ); assertEquals(m.getCurrency(), "USD" ); }
覆盖 equals 时总要覆盖 hashCode
在应用程序的执行期间,只要对象的equals方法的比较操作所用到的信息没有被修改,那么对同一个对象的多次调用,hashCode方法必须始终放回同一个值。在一个应用程序与另一个程序的执行过程中,执行hashCode方法所返回的值可以不一致。
两个对象equals调用相等,hashCode一定相等
两个对象equals调用不相等,hashCode可以一样。例如String的hashCode
1 2 3 4 5 6 7 8 9 10 11 12 13 public int hashCode () int h = hash; if (h == 0 && value.length > 0 ) { char val[] = value; for (int i = 0 ; i < value.length; i++) { h = 31 * h + val[i]; } hash = h; } return h; }
这是 HashMap 的实际的put 方法,里面通过
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 final V putVal (int hash, K key, V value, boolean onlyIfAbsent, boolean evict) Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0 ) n = (tab = resize()).length; if ((p = tab[i = (n - 1 ) & hash]) == null ) tab[i] = newNode(hash, key, value, null ); else { Node<K,V> e; K k; if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this , tab, hash, key, value); else { for (int binCount = 0 ; ; ++binCount) { if ((e = p.next) == null ) { p.next = newNode(hash, key, value, null ); if (binCount >= TREEIFY_THRESHOLD - 1 ) treeifyBin(tab, hash); break ; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break ; p = e; } } if (e != null ) { V oldValue = e.value; if (!onlyIfAbsent || oldValue == null ) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null ; }
始终要覆盖toString 下面是Spring中的抽象Bean定义类重写的hashCode()和toString()方法,重写toString()让我们能更好的debug以及了解这个类属性。String的hashCode是以31为优选乘子,选择相邻的质数也是ok的,但是31 = (2<<5) -1 ,可以被JVM优化。
不建议用 Lombok以及AutoValue 。代码是简洁了,维护起来很麻烦。
你使用了这些插件,你的组员也要用,如果你在内网开发,其他人没有这个插件,完全是个灾难。
代码是整洁了,但是维护起来很麻烦,不要图一时之快。
当然你要用,要注意用@Slf4j,而不是@Log4j,SpringBoot默认使用Logback,你指定了Log4j,就会有冲突,你换成其他日志输出框架,那就有问题。Slf4j有桥接包,屏蔽了这些内容,让你可以LoggerFactory.getLogger(xxx.class),而不用明确指定是哪个日志输出框架。
那Spring 和其他框架是怎么输出日志的呢,就是用 apache.logging包下的protected final org.apache.commons.logging.Log logger = org.apache.commons.logging.LogFactory.LogFactory.getLog(this.getClass());里面的getLog方法,再来了LogAdpter.createLog()这个 LogAdpter里面就是去找slf4j或者log4j内容,当然你用Spring Boot默认的 logback就用Slf4j再来个桥接包。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 final class LogAdapter private static final String LOG4J_SPI = "org.apache.logging.log4j.spi.ExtendedLogger" ; private static final String LOG4J_SLF4J_PROVIDER = "org.apache.logging.slf4j.SLF4JProvider" ; private static final String SLF4J_SPI = "org.slf4j.spi.LocationAwareLogger" ; private static final String SLF4J_API = "org.slf4j.Logger" ; private static final LogAdapter.LogApi logApi; private LogAdapter () } }
下面是解析 Spring 中AbstractBeanDefinition 的 toString()方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public abstract class AbstractBeanDefinition extends BeanMetadataAttributeAccessor implements BeanDefinition , Cloneable public int hashCode () int hashCode = ObjectUtils.nullSafeHashCode(this .getBeanClassName()); hashCode = 29 * hashCode + ObjectUtils.nullSafeHashCode(this .scope); hashCode = 29 * hashCode + ObjectUtils.nullSafeHashCode(this .constructorArgumentValues); hashCode = 29 * hashCode + ObjectUtils.nullSafeHashCode(this .propertyValues); hashCode = 29 * hashCode + ObjectUtils.nullSafeHashCode(this .factoryBeanName); hashCode = 29 * hashCode + ObjectUtils.nullSafeHashCode(this .factoryMethodName); hashCode = 29 * hashCode + super .hashCode(); return hashCode; } public String toString () StringBuilder sb = new StringBuilder("class [" ); sb.append(this .getBeanClassName()).append("]" ); sb.append("; scope=" ).append(this .scope); sb.append("; abstract=" ).append(this .abstractFlag); sb.append("; lazyInit=" ).append(this .lazyInit); sb.append("; autowireMode=" ).append(this .autowireMode); sb.append("; dependencyCheck=" ).append(this .dependencyCheck); sb.append("; autowireCandidate=" ).append(this .autowireCandidate); sb.append("; primary=" ).append(this .primary); sb.append("; factoryBeanName=" ).append(this .factoryBeanName); sb.append("; factoryMethodName=" ).append(this .factoryMethodName); sb.append("; initMethodName=" ).append(this .initMethodName); sb.append("; destroyMethodName=" ).append(this .destroyMethodName); if (this .resource != null ) { sb.append("; defined in " ).append(this .resource.getDescription()); } return sb.toString(); } }
谨慎地覆盖 clone 不可变的类永远都不应该提供clone方法
实际上clone方法就是另一个构造器,必须确保它不会伤害到原始的对象,并确保正确地创建被克隆对象中的约束条件(invariant)。
Cloneable架构与引用可变对象的final域的正常用法是不相兼容的。
HashMap.Entry被加强了,它支持一个“深拷贝”deepCopy();
1 2 3 4 5 6 7 8 9 10 11 12 13 @Override public Object clone () HashMap<K,V> result; try { result = (HashMap<K,V>)super .clone(); } catch (CloneNotSupportedException e) { throw new InternalError(e); } result.reinitialize(); result.putMapEntries(this , false ); return result; }
什么是深拷贝,什么是浅拷贝
Java Shallow clone
Shallow clone is default implementation in Java. In overridden clone method, if you are not cloning all the object types (not primitives(原生类型), then you are making a shallow copy.
Java Deep Copy
In the deep copy, we create a clone which is independent of original object and making changes in the cloned object should not affect original object.
考虑实现 Comparable 接口 1 2 3 public interface Comparable <T > int compareTo (T t) }
返回值规范
1 2 3 4 5 this < t => -1, this == t => 0; this > t => 1;
遵循下面几个规范
sgn(x.compareTo(y)) == -sgn(y.compareTo(x)); 类似1 == -(-1)
传递性,a>b,b>c => a>c
如果x.compareTo(y) ==0,sgn(x.compareTo(z)) == sgn(y.compareTo(z))。a==b,a.f(c) == b.f(c)
强烈建议x 比 y == 0,x.equals(y) => true,若违反了这个条件,都应该明确说明。
1 2 3 4 BigDecimal foo = new BigDecimal("1.0" ); BigDecimal bar = new BigDecimal("1.00" ); foo.equals(bar); foo.compareTo(bar);
在ocmpareTo方法中使用关系操作符 < 和 > 是非常繁琐的,而且容易出错,因此不建议使用
HashSet 会两个都存,TreeSet 只会存一个,因为利用了compareTo() 方法。
Classes and Interfaces 使类和成员的可访问性最小化 区分一个组件设计得好不好,唯一重要的因素在于,它对外部的其他组件而言,是否隐藏了其内部数据和其他实现细节。设计良好的组件会隐藏所有的实现细节,把API与实现清晰地隔离开来。然后组件之间通过API通信,一个模块不需要知道其他模块的内部工作情况。这个概念被称为信息隐藏(information hiding)/封装(encapsulation),是软件设计的基本原则之一。
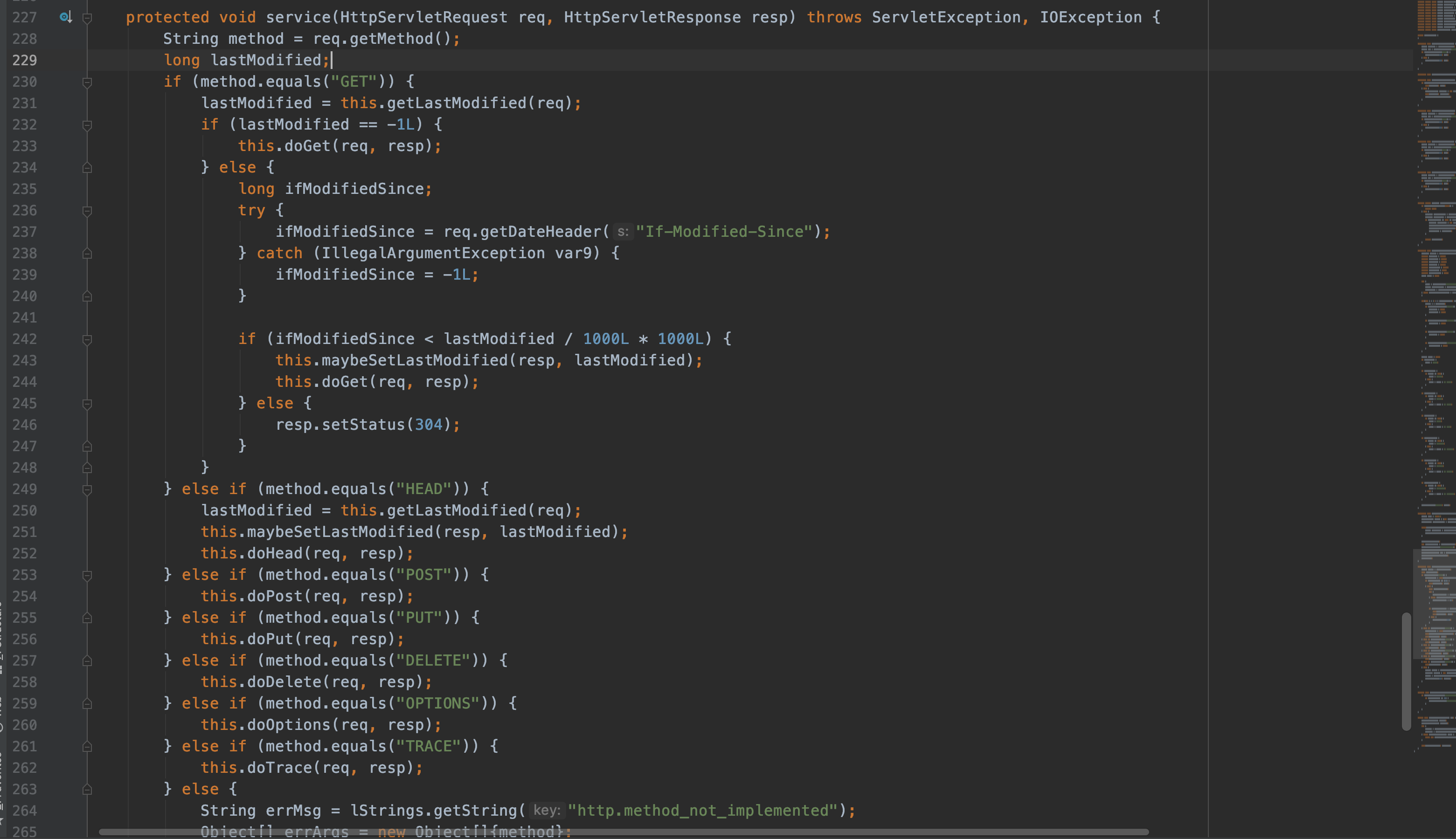
例如Spring Boot 2.0后的版本的Spring Boot,直接在https://start.spring.io直接生成就完事了,不像以前写一个Web应用先要Servlet 容器(Tomcat/Jetty/Weblogic等),再实现javax.servlet.http.HttpServlet重写它的doGet/doPost方法,甚至是service方法(不建议这么做,有关内容自己谷歌 Http Code 304),然后在 web.xml文件中添加这么一坨东西。
Java代码部分 web.xml部分 有关 304 在HttpServlet及Servlet容器的实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import java.io.*;import javax.servlet.*;import javax.servlet.http.*;public class HelloWorld extends HttpServlet public void doGet (HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { String message = "Hello World" ; response.setContentType("text/html" ); PrintWriter out = response.getWriter(); out.println("<h1>" + message + "</h1>" ); } }
1 2 3 4 5 6 7 8 9 <servlet > <servlet-name > HelloWorld</servlet-name > <servlet-class > me.young1lin.HelloWorld</servlet-class > </servlet > <servlet-mapping > <servlet-name > HelloWorld</servlet-name > <url-pattern > /HelloWorld</url-pattern > </servlet-mapping >
引用
当然这些东西不算完,还要放进Servlet容器中启动,最终返回信息。
而Spring Boot只需要简单几行代码的配置,就能启动一个web应用。
信息隐藏之所以重要,是因为
有效地解除组成系统的各组件之间的耦合关系,即解耦(decouple),使得这些组件可以独立地开发、测试、优化、使用、理解和修改。
同时减轻了维护的负担。
隐藏实现,就可以使代码组件化,如果因为哪个组件性能差,就可以单独对这个组件进行优化。
并且一个包级私有的顶层类(或者接口)只是在某一个类的内部被用到,就应该考虑使它成为唯一使用它的那个累的私有嵌套类(内部类)。像下面这样
HashMap Node部分 ArrayList 迭代器部分 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 public class HashMap <K ,V > extends AbstractMap <K ,V > implements Map <K ,V >, Cloneable , Serializable { static class Node <K ,V > implements Map .Entry <K ,V > final int hash; final K key; V value; Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) { this .hash = hash; this .key = key; this .value = value; this .next = next; } public final K getKey () return key; } public final V getValue () return value; } public final String toString () return key + "=" + value; } public final int hashCode () return Objects.hashCode(key) ^ Objects.hashCode(value); } public final V setValue (V newValue) V oldValue = value; value = newValue; return oldValue; } public final boolean equals (Object o) if (o == this ) return true ; if (o instanceof Map.Entry) { Map.Entry<?,?> e = (Map.Entry<?,?>)o; if (Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue())) return true ; } return false ; } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 public class ArrayList <E > extends AbstractList <E > implements List <E >, RandomAccess , Cloneable , java .io .Serializable private class Itr implements Iterator <E > int cursor; int lastRet = -1 ; int expectedModCount = modCount; Itr() {} public boolean hasNext () return cursor != size; } @SuppressWarnings ("unchecked" ) public E next () checkForComodification(); int i = cursor; if (i >= size) throw new NoSuchElementException(); Object[] elementData = ArrayList.this .elementData; if (i >= elementData.length) throw new ConcurrentModificationException(); cursor = i + 1 ; return (E) elementData[lastRet = i]; } public void remove () if (lastRet < 0 ) throw new IllegalStateException(); checkForComodification(); try { ArrayList.this .remove(lastRet); cursor = lastRet; lastRet = -1 ; expectedModCount = modCount; } catch (IndexOutOfBoundsException ex) { throw new ConcurrentModificationException(); } } @Override @SuppressWarnings ("unchecked" ) public void forEachRemaining (Consumer<? super E> consumer) Objects.requireNonNull(consumer); final int size = ArrayList.this .size; int i = cursor; if (i >= size) { return ; } final Object[] elementData = ArrayList.this .elementData; if (i >= elementData.length) { throw new ConcurrentModificationException(); } while (i != size && modCount == expectedModCount) { consumer.accept((E) elementData[i++]); } cursor = i; lastRet = i - 1 ; checkForComodification(); } final void checkForComodification () if (modCount != expectedModCount) throw new ConcurrentModificationException(); } } }
公有类的实例域决不能是公有的,包含公有可变域的类通常并不是线程安全的。
虽然 ClassPathXmlApplicationContext 封装做的很好,但是学习起来比较费劲。
使可变性最小化 善用final、加上final的静态工厂,享元模式。BigDecimal.ZERO,Integer的自动拆装箱里面的CacheInteger类。
复合优于继承 我觉得更优的翻译应该叫组合优于继承。当然,不是所有情况下都要用组合。《UNIX 编程艺术》中也提到,善用组合。
下面是 Spring 基石 GenericApplicationContext 中的源码,其中 DefaultListableBeanFactory 才是真正的容器。这个叫组合模式,两者都实现了同一个接口(BeanFactory),这里的 DefaultListableBeanFactory 可以是一个至多个,然后依次调用,直到返回结果为止。
1 2 3 4 5 6 7 8 9 10 11 12 13 public class GenericApplicationContext extends AbstractApplicationContext implements BeanDefinitionRegistry private final DefaultListableBeanFactory beanFactory; @Override public final ConfigurableListableBeanFactory getBeanFactory () return this .beanFactory; } }
用内含的方式实现,例如JFinal中的Record对象,内含了一个HashMap对象,来实现一些操作。万物(单条数据)皆为Record。
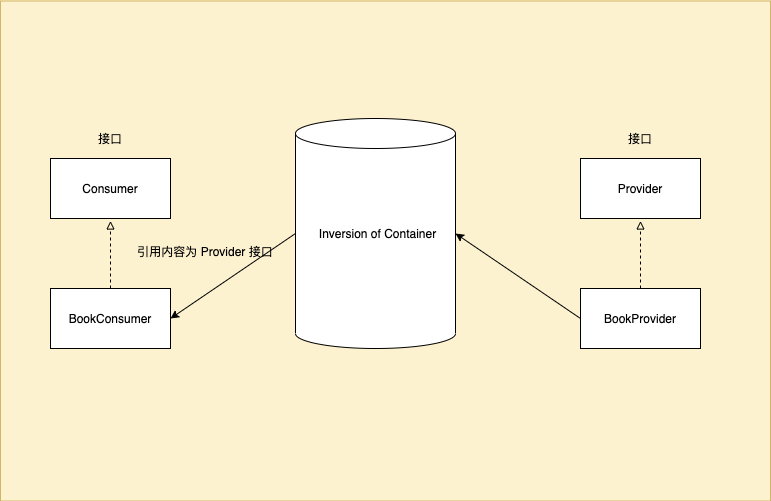
Spring 中 ApplicationContext 类型的对象就是内涵了个 BeanFactory,其实就是 DefaultListableBeanFactory,也就是所谓的 IoC (Inversion of Control)容器。
要么设计继承并提供文档说明,要么禁止继承 类必须精心挑选的受保护的(protected)方法,提供适当的钩子(hook),一边进入其内部工作中。
因为要符合里氏替换原则,之后开发的人,并不清楚你现在的类是什么意思。
接口优于抽象类 类是单继承,接口可以多实现,多接口可以实现不同业务需求,由于1.8后可以用default修饰接口方法,实现和抽象类一样的效果,又可以有实体方法,又有待子类实现的抽象方法。
Netty 中的 ChannelInboundHandler 就是个很好的例子。
多个接口方法同名,实现类报错
1 2 3 4 5 6 7 8 9 interface A int f () } interface B void f () } class C implements A ,B int f () }
接口是高度抽象的结果,而抽象类
为后代设计接口 慎用 default 去修饰接口方法
BeanFactory 接口定义了最基本的容器功能。
接口只用于定义类型 常量接口模式是对接口的不良使用
1 2 3 public interface XXXConstants static final String MY_CONSTANTS = "my constants " ; }
java.io.ObjectStreamConstants 是个反例
如果要去定义常量
要么在类内部定义,想 Integer.MAX_VALUE,BigDecimal.ZERO等等
要么用枚举实现,像我自定义的状态信息
接口应该用来定义类型。
类层次优先于标签类 字面意思。
像这种 AbstractApplicationContext 继承自 DefaultResourceLoader,拥有了资源加载的能力,像 EventObject 这种就是标记类,你可以加上,也可以不加,但是这是约定俗称的事件对象的类。
著名的标签接口(tagging interface)java.util.EventListener、java.lang.Serializable。注意这里是接口,平常项目开发也是会自己定义标记接口的,里面没有任何方法(行为),仅起到标记作用。这个是约定俗称的内容,你不遵守,等待的就是报错(例如 Java 序列化没有实现 Serializable 接口,就会报错)。
1 2 3 4 5 6 public interface EventListener }
静态成员类优先于非静态成员类 Builder
Map.Entry
限制源文件为单个顶级类(public 修饰与文件名相同的类) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class A static final String NAME = "pan" ; } class B static final String NAME = "cake" ; } public class B static final String NAME = "bar" ; } class A static final String NAME = "foo" ; } public class C public static void main (String[] args) System.out.println(A.NAME+B.NAME); } }
这样有歧义,编译不给过,分开存。如果一定要放一起,就放在顶级类内部做静态成员类。
Generics 翻译版本有误,SINCE Java 5, generics have been a part of the language. 翻译版本少了个 s 变成了 generic。因为 Think in Java 英文版中, generics 才是代表泛型。
不要使用原生态类型 1 2 3 4 5 6 7 List apples = new ArrayList(1 <<4 ); List<Apple> apples = new ArrayList (1 <<4 ); apples.add(new Banana());
List 和 List<Object> 是有区别的,后者明确告诉该容器接受所有任意类型对象。
必须在类文字(class literal)中使用原生态类型
1 private static final Logger log = LoggerFactory.getLogger(User.class ) ;
消除非受检的警告 /uncheck/
⬆️尽量不要编译后出现这个(其实就是@SuppreWarnings("unchecked")),除非可以证明引起警告的代码是类型安全的,用 /uncheck/ 或者 @SuppreWarnings("unchecked")来禁止警告。尽可能在小的范围使用这个注解,像 synchronized 以及catch Exception 一样,尽可能精准,细粒度去做。这样好调试啊。
书上讲的 ArrayList.toArray(T[] a)方法,在 JDK1.8 中,源码是把去警告的注解放在方法上的,和他推荐的不一样。当然还是按照作者推荐的,这样让后人更容易懂你写的代码,尽量别写出祖传代码.
1 2 3 4 5 6 7 8 9 10 @SuppressWarnings ("unchecked" )public <T> T[] toArray(T[] a) { if (a.length < size) return (T[]) Arrays.copyOf(elementData, size, a.getClass()); System.arraycopy(elementData, 0 , a, 0 , size); if (a.length > size) a[size] = null ; return a; }
列表优先于数组 除非写游戏类的,用二维数组表示坐标什么的,科学计算用基础类型。
1 2 3 4 5 6 7 Object[] o = new Long[1 ]; objectArray[0 ] = "str" ; List<Object> o2 = new ArrayList<Long>(); ol.add("str" );
范型数组不存在,编译不通过。
列表帮你做好了动态扩容,类型转换等操作。
优先考虑范型 1 2 <T> T query (Class<T> clazz) ;
优先考虑范型方法 ⬆️ 像上面这种
善用通配符,E Element,T type表示具体的类型,K V key Value,? 不确定什么类型
JDK1.7引入@SafeVarargs 放在方法上,消除使用范型方法警告
利用有限制通配符来提升 API 的灵活性 1 2 3 4 5 List<T extends Record> list; public boolean isContainAnnotation (Object target,Class<? extends Annotation> clazz) return null == target.getClass().getAnnotation(clazz); }
谨慎使用并用范型和可变参数 《阿里巴巴 Java 开发规范》中也明确指出了,少用甚至不用可变参数,这是个语法糖。
1 2 public void foo (List<String>... stringLists) ;
如果真的方法是安全的,对于每一个带有范型可变参数或者参数化类型的方法,都要用@SafeVarargs进行注解.
优先考虑类型安全的异构容器 以前写的手动分页的类。,List<E> Set<E> Map<K,V>
1 2 3 4 5 6 public class Page <E > private int index; private int size; private E[] list; }
Enums and Annotations 用 enum 代替 int 常量 Java 的枚举本质上是int 值。《深入理解 Java 虚拟机》介绍了枚举类其实是隐式继承了 java.lang.Enum这个类,所以枚举不能继承其他类,只能实现接口。
Java enums can extend java.lang.Enum class implicitly (隐含的), so enum types cannot extend another class.
1 2 3 4 5 6 7 8 9 public class SomeThingStatus public static final int Y = 1 ; public static final int N = 0 ; } public enum Status{ Y,N }
根据枚举所作用的范围,尽可能贴合实际使用范围来定义枚举类该在类私有/包级私有/顶层类(top-level class)/顶层类的成员类。
策略模式枚举
trategy enum
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public enum PayrollDay{ MONDAY,TUESEDAY,WEDNESDAY,THURSDAY,FRIDAY,SATURDAY(PayType.WEEKEND),SUNDAY(PayType.WEEKEND); private final PayType payType; PayrollDay(PayType paytype){this .payType = payType;} PayrollDay(){return this (PayType.WEEKDAY);} int pay (int minutesWorked, int payRate) return payType.pay(minutesWorked, payRate); } private enum PayType{ WEEKDAY{ int overtimePay (int minsWorked, int payRate) return minisWorked <= MINIS_PER_SHIT ? 0 : (minsWorked - NINS_PER_SHIFT) * payRate / 2 ; } }, WEEKEND{ int overtimePay (int minsWorked, int payRate) return minsWorked * payRate / 2 ; } } abstract int overtimePay (int mins,int payRate) private static final int MINIS_PER_SHIFT = 8 * 60 ; int pay (int minsWorked, int payRate) int basePay = minsWorked * payRate; return basePay + overtimePay(minsWorked, payRate); } } }
每当需要一组固定的常量,并且在编译时就知道其成员的时候,就应该使用枚举。如菜单的选项、操作代码以及命令行标记等。
策略模式 如 org.springframework.core.io.Resource
UrlResource: 访问网络资源的实现类。ClassPathResource: 访问类加载路径里资源的实现类。FileSystemResource: 访问文件系统里资源的实现类。ServletContextResource: 访问相对于 ServletContext 路径里的资源的实现类.InputStreamResource: 访问输入流资源的实现类。ByteArrayResource: 访问字节数组资源的实现类。
责任链模式,例如 Handler Interceptor,Filter 。如下所示:
DispatcherServlet 中的 service 方法,经过一些校验和一些参数设置,最终会调用这个方法,如果你懂了这个方法,Spring MVC 一般的情况都能 Hold 住了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 protected void doDispatch (HttpServletRequest request, HttpServletResponse response) throws Exception HttpServletRequest processedRequest = request; HandlerExecutionChain mappedHandler = null ; boolean multipartRequestParsed = false ; WebAsyncManager asyncManager = WebAsyncUtils.getAsyncManager(request); try { try { ModelAndView mv = null ; Object dispatchException = null ; try { processedRequest = this .checkMultipart(request); multipartRequestParsed = processedRequest != request; mappedHandler = this .getHandler(processedRequest); if (mappedHandler == null ) { this .noHandlerFound(processedRequest, response); return ; } HandlerAdapter ha = this .getHandlerAdapter(mappedHandler.getHandler()); String method = request.getMethod(); boolean isGet = "GET" .equals(method); if (isGet || "HEAD" .equals(method)) { long lastModified = ha.getLastModified(request, mappedHandler.getHandler()); if ((new ServletWebRequest(request, response)).checkNotModified(lastModified) && isGet) { return ; } } if (!mappedHandler.applyPreHandle(processedRequest, response)) { return ; } mv = ha.handle(processedRequest, response, mappedHandler.getHandler()); if (asyncManager.isConcurrentHandlingStarted()) { return ; } this .applyDefaultViewName(processedRequest, mv); mappedHandler.applyPostHandle(processedRequest, response, mv); } catch (Exception var20) { dispatchException = var20; } catch (Throwable var21) { dispatchException = new NestedServletException("Handler dispatch failed" , var21); } this .processDispatchResult(processedRequest, response, mappedHandler, mv, (Exception)dispatchException); } catch (Exception var22) { this .triggerAfterCompletion(processedRequest, response, mappedHandler, var22); } catch (Throwable var23) { this .triggerAfterCompletion(processedRequest, response, mappedHandler, new NestedServletException("Handler processing failed" , var23)); } } finally { if (asyncManager.isConcurrentHandlingStarted()) { if (mappedHandler != null ) { mappedHandler.applyAfterConcurrentHandlingStarted(processedRequest, response); } } else if (multipartRequestParsed) { this .cleanupMultipart(processedRequest); } } }
用实例域代替序数(表示次序的数目) 实例域 ONE(1),TWO(2)
用 EnumSet 代替位域 让你用 OR 位运算将几个常量合并到一个集合中,称作位域(bit field)
Set set = EnumSet.of(ONE,TWO);
用 EnumMap 代替序数索引 麻烦,平时用不到
用接口模拟可扩展的枚举 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public interface Foo void bar (String operation) } public enum SubFoo implements Foo{ A("a" ){ @Override public void bar (String operation) System.out.println("a" +operation); } }, B("b" ){ @Override public void bar (String operation) System.out.println("b" +operation); } }; private String s; SubFoo(String s){ this .s = s; } }
注解优先于命名模式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Transactional (rollbackFor = Exception.class ) public boolean updateUser (User user ) return userRepository.updateUser(user); } @ExceptionHandler (BindException.class ) public ApiReturnObject defaultExceptionHandler (BindException bindException ) List<ObjectError> errors = bindException.getBindingResult().getAllErrors(); if (errors.size()>0 ){ ObjectError objectError = errors.get(0 ); ResultCode resultCode = ResultCode.FAILURE.setMessage(objectError.getDefaultMessage()); return ApiReturnUtil.failure(resultCode); } return ApiReturnUtil.failure(ResultCode.SYSTEM_EXCEPTION); }
坚持使用 @Override 注解 保证写的代码,在编译时能检查得出来到底有没有重写 父类/接口 的方法。
用标记接口定义类型 Spring 中的所有事件,默认继承 EventObject 这个也算是“接口”,一个不成文的规定。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class UserEntity implements Serializable private int id; private transient BigDecimal salary; } @Service @Repository @Compment
Lambdas and Streams Lambda 优先于匿名类 接口只有一个待实现方法时,可以转换成Lambda 写法。如下
1 2 3 4 5 6 public interface SayHelloInterface String sayHello () ; } public static void main (Stirng[] args) SayHelloInterface hello = () -> "hello" ; }
还有 Comparable<T>就是很好用 Lambda 写法的例子,而不是用匿名类去写。
如果 Lambda 没有名称和文档,并且有很多行,那就不要用。
方法引用优先于 Lambda 1 2 System.out::println Integer::parseInt
方法引用详情见 《Java 8 实战》
坚持使用标准的函数接口
接口
函数签名
范例
UnaryOperator
T apply(T t)
String::toLowerCase
BinaryOperator
T apply(T t1,T t2)
BigInteger::add
Predicate
boolean test(T t)
Collection::isEmpty
Function<T,R>
R apply(T t)
Arrays::asList
Supplier
T get()
Instant::now
Consumer
void accept(T t)
System.out::println,Iterable::forEach
1 2 3 4 5 6 7 8 9 default void forEach (Consumer<? super T> action) Objects.requireNonNull(action); for (T t : this ) { action.accept(t); } } Supplier<Instant> supplier = () -> (Instant.now());
@FunctionalInterface
这个注解有三个目的,
告诉这个类及其文档的读者,这个接口是针对 Lambda 设计的。
这个接口不会进行编译,除非它只有一个抽象方法
避免后续维护人员不小心给该接口添加抽象方法
必须使用这个注解对自己编写的函数接口进行标注。
谨慎使用 Stream 不建议使用 Stream 来进行 SQL 查询之类的操作。
过度地使用函数式编程,会导致代码可读性变差,强调不要滥用
Methods 检查参数的有效性 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public void validate (String str,Collection collection,Object obj) if (StringUtils.isEmpty(str)){ throw new RuntimeException(); } if (CollectionUtils.isEmpty(collection)){ throw new RuntimeException(); } Objects.requireNonNull(obj,"obj is null" ); } private void a (String str) assert str.length = 1 ; }
必要时进行保护性拷贝 对于参数类型可以被不可信任方子类化的参数,请不要使用 clone 方法进行保护性拷贝。
谨慎设计方法签名 代码整洁之道
对于参数类型,优先使用接口而不是具体实现类。
1 2 3 4 5 6 7 8 9 10 11 12 13 public interface BeanDefinitionRegistryPostProcessor extends BeanFactoryPostProcessor void postProcessBeanDefinitionRegistry (BeanDefinitionRegistry registry) throws BeansException }
boolean 参数,优先使用两个元素的枚举类型。
慎用重载 不要在重载方法中使用范型,或者继承关系类型。如
1 2 3 getAll(List<?> list); getAll(Collection<?> collection);
需要调用哪个重载方法是在编译时作出决定的。
对于重载方法的选择是静态的,而对于被覆盖的方法的选择则是动态的。
慎用可变参数 可变参数其实是个语法糖
每次调用可变参数方法都会导致一次数组分配和初始化。有性能问题。可以适当的利用重载方法,替代可变参数方法。当然方法参数超过3个,就一起用可变参数,具体方法参数内容可以参考《代码整洁之道》。
最理想的参数数量是零,其次是一,再次是二,尽量避免三。有足够特殊的理由才能用三个以上参数(阿里巴巴Java开发手册:相同参数类型,相同业务含义,才可以使用 Java 的可变参数,可变参数放在最后,尽量不用可变参数,避免使用 Object)。
很久以前记的《代码整洁之道》的笔记
返回零长度的数组或者集合,而不是 null 1 2 3 4 5 6 7 8 9 10 11 public byte [] getDigestKeyGen(String content){ byte [] bytes = {}; try { bytes = xxxx; }catch (Exception e){ } return bytes; }
谨慎返回 optional 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 private Optional<?> createOptionalDependency( DependencyDescriptor descriptor, @Nullable String beanName, final Object... args) { DependencyDescriptor descriptorToUse = new NestedDependencyDescriptor(descriptor) { @Override public boolean isRequired () return false ; } @Override public Object resolveCandidate (String beanName, Class<?> requiredType, BeanFactory beanFactory) return (!ObjectUtils.isEmpty(args) ? beanFactory.getBean(beanName, args) : super .resolveCandidate(beanName, requiredType, beanFactory)); } }; Object result = doResolveDependency(descriptorToUse, beanName, null , null ); return (result instanceof Optional ? (Optional<?>) result : Optional.ofNullable(result)); } private final T value;private static final Optional<?> EMPTY = new Optional<>();
常用的方法 Optional.ofNullable(result),返回一个Optional(null)或者 Optional 的包装对象的。
Optional<T> 类代表的是一个不可变的容器,它可以存放单个非 null 的 T 引用,或者什么内容都没有 。
永远不要通过返回 Optional 的方法返回 null,因为它彻底违背了 optional(可选的) 的本意。
容器类型含集合、映射、Stream、数组和optional,都不应该被包装在 optional 中。
永远不要返回基本包装类型的 optional 。已经提供了 OptionalInt,OptionalDouble,OptionalLong等。
永远都不适合用 optional 作为键、值,或者集合或做数组中的元素。
尽量不要将 Optional 用作返回值以外的任何其他用途。
用了 Optional,你就必须在调用方,做相应的判断,因为如果使用 Optional.ofNullable(obj)它有最差返回 private static final Optional<?> EMPTY = new Optional<>();
为所有到处的 API 元素编写文档注释 《代码整洁之道》—— 最好的注释是方法本身(见名知意、简短 不超过 50 行、方法参数最好不要超过 3 个、少用可变参数)。
当然这是一种比较极端的说法,好的 API 应该至少写出 what why how,这个方法是什么,为什么这么实现,以及如何使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 <T> T getBean (String name, Class<T> requiredType) throws BeansException ;
使用{@literal}忽略尖括号等需要转义的内容。如 {@literal r < 1}
General Programing 将局部变量的作用域最小化 只在需要用到变量的前一步,去声明变量。
下面是AutowiredAnnotationBeanPostProcessor覆盖SmartInstantiationAwareBeanPostProcessor的方法。
具体执行步骤 AbstractAutowireCapaleBeanFactory#doCreateBean -> AbstractAutowireCapaleBeanFactory#createBeanInstance -> AbstractAutowireCapaleBeanFactory#determineConstructorsFromBeanPostProcessors -> SmartInstantiationAwareBeanPostProcessor#determineCandidateConstructors ->AutowiredAnnotationBeanPostProcessor#determineCandidateConstructors
在属性填充之前,创建 beanWrapper。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 @Override @Nullable public Constructor<?>[] determineCandidateConstructors(Class<?> beanClass, final String beanName) throws BeanCreationException { if (!this .lookupMethodsChecked.contains(beanName)) { try { ReflectionUtils.doWithMethods(beanClass, method -> { Lookup lookup = method.getAnnotation(Lookup.class ) ; if (lookup != null ) { Assert.state(this .beanFactory != null , "No BeanFactory available" ); LookupOverride override = new LookupOverride(method, lookup.value()); try { RootBeanDefinition mbd = (RootBeanDefinition) this .beanFactory.getMergedBeanDefinition(beanName); mbd.getMethodOverrides().addOverride(override); } catch (NoSuchBeanDefinitionException ex) { throw new BeanCreationException(beanName, "Cannot apply @Lookup to beans without corresponding bean definition" ); } } }); } catch (IllegalStateException ex) { throw new BeanCreationException(beanName, "Lookup method resolution failed" , ex); } this .lookupMethodsChecked.add(beanName); } }
for 循环优先于 while 循环
优先使用 foreach 而不是 for 简洁、灵活、预防出错(当然在里面删除元素又进行遍历,是不行的)
不要在 foreach(增强 for 循环) 里面进行删除集合内部元素的操作。如果必要,请使用迭代器。
什么时候不该用 foreach
解构过滤:就是上面的情况,使用 Collection#removeIf。
转换:就是要明确知道要替换的元素在哪几位的时候,予以替换的时候。
平行迭代:多层迭代,例如排序算法
正确的在遍历时删除元素
1 2 3 4 5 6 7 8 9 public void filter (List<User> users) Iterator<User> it = users.iterator(); while (it.hasNext()){ User user = it.next(); if (user != null && "zhangSan" .equals(user.name)){ it.remove(); } } }
了解和使用类库 从 Java7 开始该使用 ThreadLocalRandom 而不是 Random
熟悉 java.lang、java.util、java.io及其子包中的内容。子包包括但不限于 java.util.concurrent,java.util.regex。
如果需要精确的答案,避免使用 float 和 double float、double 适合科学计算。
使用 BigDecimal、Joda Money 进行金额计算。
JavaScript
Java
1 2 3 4 5 double a = 0.1 ;double b = 0.3 ;System.out.println(b-a == 0.2 ); double d = b-a;System.out.println(d);
基本类型优先于装箱基本类型 基本类型比包装类型更省内存,性能更高。当然,业务对性能要求不是非常高的,可以用装箱的类型。
自动拆装箱会带来一些隐藏的问题,在《阿里巴巴 Java 开发手册》中介绍,统一使用装箱类型。
如果基本类型和装箱基本类型混合使用,装箱基本类型则会自动拆箱。
自动拆装箱本质上是为了简化开发,添加此类语法糖。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 List<Integer> list = new ArrayList<>(2 ); list.add(1 ); Integer a = 129 ; a = 1 * a; public static Integer valueOf (int i) if (i >= IntegerCache.low && i <= IntegerCache.high) return IntegerCache.cache[i + (-IntegerCache.low)]; return new Integer(i); }
如果其他类型更合适,尽量避免使用字符串 不适合代替枚举类型的值、聚合类型、能力表(capabilities)。
ThreadLocal 如果用 String 作为 Key,那将是全局共享的,不妥。
1 2 3 4 String compoundKey = className + "#" + i.next(); String methodName = className + "#" + methodName;
1kb = 1024 byte = 1024 * 8 bit
数据类型
名称
长度
备注
byte
字节型
8bit
表示数据范围:-128~127
short
短整型
16bit
char
字符型
16bit
int
整型
32bit
long
长整型
8 byte
float
单精度浮点型
4 byte
精度:7-8位
double
双精度浮点型
8 byte
boolean
布尔型
true/false
实际用 byte 存储,0 为 false,1 为 true
选择合适的类型,能使得占用内存更小。
当然,为防止伪共享,提高 CPU 执行效率,如果使用 volatile 关键字禁止 CPU 缓存,如果需要提升代码性能,需要额外填充其他对象。
如果一个对象包含线程局部变量且尺寸小于 64byte,就有可能发生伪共享。在Java7之前,一般通过对象填充的方式来避免伪共享问题:
1 2 3 4 5 6 7 8 9 10 private static final class PaddedVolatileLong private volatile long v; private long p1, p2, p3, p4, p5, p6; } @sun .misc.Contendedpublic class ForkJoinPool extends AbstractExecutorService }
需要给JVM加上启动项参数:
-XX:-RestrictContended
Hotspot虚拟机文档 “oops/oop.hp”有对Markword字段的定义
1 2 3 4 5 6 64 bits: -------- unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object) JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object) PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object) size:64 ----------------------------------------------------->| (CMS free block)
1 2 3 4 5 6 class Fruit extends Object private int size; } Object object = new Object(); Fruit fruit = new Fruit();
Object 对象,Markword 8 个字节,kclass 4 个字节, 加起来 12 个字节,加上 4 个字节的对齐填充,占用的空间是 16 个字节。
Fruit 对象, Markword 8 个字节,kclass 4 个字节,还有个 size 成员变量,int类型占 4 个字节,加起来是 16 个字节,不需要对齐填充
缓存行非64字节宽的处理器。如P6系列和奔腾处理器,它们的L1和L2高速缓存行是32个字节宽。
共享变量不会被频繁地写。因为使用追加字节的方式需要处理器读取更多的字节到高速缓冲区,这本身就会带来一定的性能消耗,如果共享变量不被频繁写的话,锁的几率也非常小,就没必要通过追加字节的方式来避免相互锁定。
了解字符串连接的性能 避免在循环使用 + 拼接字符串
1 2 3 4 5 6 7 8 9 10 for (int i = 0 ;i < 1000 ;i++){ String str = "1" + strs[i]; }
通过接口引用对象 1 List<User> list = new ArrayList<>();
更加灵活。
样例 实际碰到的。
1 2 3 4 5 @GetMapping public ArrayList<Object> getList () ArrayList<Object> list = aService.getList(); return list; }
当我需要按照构造器传入的 size 来截取 List,因为我客户端需要根据 pageSize 来获取指定 size 或小于该大小的数据。
1 2 3 4 5 6 @GetMapping public ArrayList<Object> getList () ArrayList<Object> list = aService.getList(); SubList subList = list.subList(0 ,10 ); return new ArrayList(subList); }
我只是需要个 JSON 数组,我并不需要 ArrayList 的特殊的方法,这样就是严重耦合 的代码。
这个改成下面的,是不是更好点?
1 2 3 4 5 @GetMapping public List<Object> getList () List<Object> list = aService.getList(); return list.subList(0 ,10 ); }
Spring 中大量使用接口来引用,而非具体实现类。代码尽量使用依赖注入接口类型,实现实际类与调用类解耦。
如果没有合适的接口,就用类层次结构中提供了必要功能的最小的具体类 来引用对象。
即如果要使用ArrayList.trimToSize()就声明为 ArrayList 引用,这是一种编程习惯,只用你用到的,只提供你想给外部调用的,不是全部,是部分(部分可以是全部)。
Spring 中是采用的流水线的思维方式,将各个阶段,抽象了出来,每个阶段都有其对应的接口抽象。
每个阶段的抽象。
BeanFactory
Resource
BeanDefinition
BeanWrapper
每个阶段中的前置后置处理抽象
BeanFactoryPostProcessor(BeanFactory 启动的时候,可以在 AbstractApplicationContext#invokeBeanFactoryPostProcessors 中找到答案,打断点,自己慢慢看,就知道 @Component 是在这里的哪一步解析的了,启动一个随便什么的 Spring Boot 项目,即可查看具体内容)
BeanDefinitionRegistryPostProcessor(BeanDefnition 注册的时候)
MergedBeanDefinitionPostProcessor(GenericBeanDefinition 和其他 BeanDefinition 有个合并的过程,合并成 RooBeanDefinition,如果你看过小马哥的讲解的,这个其实是 XML 配置里面会出现的情况,一个 <bean/> 就是一个 RootBeanDefinition,当然,它会先包装成 GenericBeanDefinition 再进行合并)
SmartInstantiationAwareBeanPostProcessor(一般带 Smart 的,都要先一步执行,例如 SmartInitializingSingleton,会在单例对象预实例化 阶执行,SmartInstantiationAwareBeanPostProcessor 的实现的抽象类 AbstractAdvisorAutoProxyCreator 和 AOP 相关,就在这一步,对要拦截的 Bean 进行拦截,然后代理,这里会有 Pattern 正则来匹配的过程,@Transaction 也是在这一步做的)
InstantiationAwareBeanPostProcessor
DestructionAwareBeanPostProcessor
BeanPostProcessor(上面所有 BeanPostProcessor 的父类,就是最卑微的,最后执行)
接口优先于反射机制 详情见
Spring BeanProcessor
InitializingBean 和 DisposableBean,它们也可以用 @PostConstruct 和 @PreDestroy 代替,当然,两者一起也是可以的,具体执行顺序。
Spring MVC Interceptor
给定了模版类,调用模版类的模版方法。
如果使用反射机制
损失了编译时类型检查的优势
执行反射访问所需要的代码非常笨拙和冗长
性能损失
谨慎使用本地方法 native method 是与平台相关的,破坏了 Java 的移植性,如非必须情况,要避免使用本地方法。
可能的必要情况
需要调用 dll 文件
需要真正高性能的高精度算术运算。
谨慎地进行优化 不等同于不要持续重构代码
遵守普遍接受的命名惯例
包名com.xxxx,域名反写
类名 抽象类,BaseXXXXX,AbstractXXXXXX
变量名 局部变量名,String xxxStr,
方法名 方法名应该是个动词,如 createBean,getBean,表示的是类的行为。
get 是获取单个对象,list 是获取多个对象。
题外话 怪罪于 StringBuilder sb = new StringBuilder(100); 命名为 sb 的人,是真的 SB。本来就是局部变量用于拼接字符串的,没有很大的实际意义。
有些现代工具(MyBatis)依赖 Beans 命名惯例,setter getter,从数据库中取出值后,赋值需要调用 setter 类型方法。
Exception 只针对异常的情况才使用异常 不要将异常作为普通的控制流。
对可恢复的情况使用受检异常,对编程错误使用运行时异常 1 2 3 4 5 6 7 8 9 10 try { Class.forName("com.xxx.Driver" ); }catch (ClassNotFoundException e){ } int foo = 1 /0 ;
避免不必要地使用受检异常 可以适当将 try catch 块重构为 if else 块。
优先使用标准的异常 类越精简,加载类的速度越快,优先使用专家级的定义的异常。加粗表示更为高频使用的,如
抛出与抽象对应的异常 更高层的实现应该捕获底层的异常,同时抛出可以按照高层抽象进行解释的异常。
如果在 MyBatis 中,写 resultType 写成不存在的类,会先抛出 ClassNotFoundException,然后层层抛出,到 Spring 创建 Bean 的步骤中。最终由 Servlet 容器捕获,然后停止启动项目。可以自己手动试试 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 protected BeanWrapper autowireConstructor (String beanName, RootBeanDefinition mbd, @Nullable Constructor<?>[] ctors, @Nullable Object[] explicitArgs) return (new ConstructorResolver(this )).autowireConstructor(beanName, mbd, ctors, explicitArgs); } try { Object autowiredArgument = resolveAutowiredArgument( methodParam, beanName, autowiredBeanNames, converter, fallback); args.rawArguments[paramIndex] = autowiredArgument; args.arguments[paramIndex] = autowiredArgument; args.preparedArguments[paramIndex] = new AutowiredArgumentMarker(); args.resolveNecessary = true ; } catch (BeansException ex) { throw new UnsatisfiedDependencyException( mbd.getResourceDescription(), beanName, new InjectionPoint(methodParam), ex); }
异常链(exception chaining),如果低层的异常对于调试导致高层异常的问题非常有帮助,使用异常链就很合适。Spring 就是这样。
实际 WEB 开发也是不要将异常捕获,尽量将异常向上抛出,最终由 容器/框架 *进行 * 捕获/抛出 。编写自定义含 @ExceptionHandler的类,进行捕获异常。
如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @RestControllerAdvice public class GlobalExceptionHandler @ExceptionHandler (BindException.class ) public ResponseEntity <?> defaultExceptionHandler (BindException bindException ) { List<ObjectError> errors = bindException.getBindingResult().getAllErrors(); if (!CollectionUtils.isEmpty(errors)) { ObjectError objectError = errors.get(0 ); ResultCode resultCode = ResultCode.FAILURE.setMessage(objectError.getDefaultMessage()); return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR).body(resultCode); } return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR).build(); } }
注意⚠️
这里必须使用 ResponseEntity,不要自定义的什么乱七八糟的返回,没有必要再套一层,HTTP 早就想到了,不要 像下面这样返回!!多此一举,如果这么做,多半不了解 HTTP 的一些细节内容,前人早就帮你想好了。
1 2 3 4 5 { "code" : "404" , "message" : "can't find any matches response" , "data" : "404" }
这样做,只会徒增前端的负担。
每个方法抛出的所有异常都要建立文档 永远不要声明一个公有方法直接 “throws Exception”。无法让调用者判断该如何解决并捕获该异常。
有个例外,就是 main 方法,它可以被安全地声明抛出 Exception,因为它只通过虚拟机调用。
还有就是 Spring Boot 的 CommandRunner,ApplicationRunner 以及 Spring 的 InitializingBean。注意这里的 @throws 需要你写清楚,像下面那样。如何写,在我的另一个我在公司分享的【代码规范】文章里面有讲解、翻译。
1 2 3 4 5 6 7 8 9 10 11 12 13 public interface InitializingBean void afterPropertiesSet () throws Exception }
在细节消息中包含失败-捕获信息 为了捕获失败,异常的细节信息应该包含“对该异常由贡献”的所有参数和域的值。
以下是 Spring 启动创建 Bean 时失败,抛出异常的堆栈异常信息。PS:就是上面说的 MyBatis 改了 resultType 的异常。这里就是按层级抛出异常的案例 。注意:Spring 是以流水线(Pipeline)的形式来处理的 Bean,看过卓别林的《摩登时代》里面就有他在拧螺丝,是流水线上的一环,也是一个阶段的处理者。流水线是福特提出的,并且作用于福特汽车的生产,极大得提高了生产力。在软件行业同样适用,如果你懂了 Spring 是流水线的处理思想(没什么书上提到流水线和 Spring 的关系),你就懂了大半的 Spring,其他的注解解析,派生等等内容都不难。思想很重要,每个人都需要拥有多个学科的知识,例如达芬奇是画家 、科学家、发明家。这个观念在查理·芒格的《穷查理宝典》中反复被提及,值得一看的书籍。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'callEvaluationController' defined in file [/IdeaProjects/evaluation/target/classes/cn/luckyray/evaluation/api/CallEvaluationController.class]: Unsatisfied dependency expressed through constructor parameter 0; nested exception is org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'userServiceImpl' : Unsatisfied dependency expressed through method 'setUserMapper' parameter 0 ; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'userMapper' defined in file [/IdeaProjects/evaluation/target/classes/cn/luckyray/evaluation/dao/main/UserMapper.class]: Cannot resolve reference to bean 'mainSqlSessionTemplate' while setting bean property 'sqlSessionTemplate'; nested exception is org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'mainSqlSessionTemplate' defined in class path resource [cn/luckyray/evaluation/config/DataSourceConfig.class]: Unsatisfied dependency expressed through method 'sqlSessionTemplate' parameter 0; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'mainSqlSessionFactory' defined in class path resource [cn/luckyray/evaluation/config/DataSourceConfig.class]: Bean instantiation via factory method failed; nested exception is org.springframework.beans.BeanInstantiationException: Failed to instantiate [org.apache.ibatis.session.SqlSessionFactory]: Factory method 'sqlSessionFactory' threw exception; nested exception is org.springframework.core.NestedIOException: Failed to parse mapping resource: 'file [/IdeaProjects/evaluation/target/classes/mapping/main/UserMapper.xml]' ; nested exception is org.apache.ibatis.builder.BuilderException: Error parsing Mapper XML. The XML location is 'file [/IdeaProjects/evaluation/target/classes/mapping/main/UserMapper.xml]'. Cause: org.apache.ibatis.builder.BuilderException: Error resolving class. Cause: org.apache.ibatis.type.TypeException: Could not resolve type alias 'java1.lang.Integer'. Cause: java.lang.ClassNotFoundException: Cannot find class: java1.lang.Integer
不要在细节消息中包含密码、密钥以及类似的信息。输出异常消息日志时,或者正常日志时,一定要对敏感信息(用户名密码,用户名等等信息)进行脱敏操作。
努力使失败保持原子性 一般而言,失败的方法调用应该使对象保持在被调用之前的状态。
使用 JDBC 操作数据库进行增/删/改时,出现失败的情况,应该进行事务回滚。
分布式系统中的 GET 操作即使失败,也要保持幂等性。
// TODO Spring Cloud 的中就是这么 GET 默认为幂等的,会一直调用,直到你没出错为止。这个就需要提到 HATEOS 以及 RESTful 的一些约定的一些内容。
不要忽略异常 空的 catch 块会使异常达不到应有的目的。
如果选择忽略异常,catch 块中应该包含一条注释,说明情况,并将异常变量命名成 ignored
1 2 3 4 5 try {}catch (TimeoutException | ExecutionException ignored){ }
Concurrency 同步访问共享的可变数据 不要使用 Thread#stop 方法。
除非读和写操作都被同步,否则无法保证同步能起作用。
避免线程不安全的条件,可以有,避免共享,没有共享就没有伤害,使用 Synchronized/volatile/Atomic 类保证线程安全。
避免过度同步 使用 JUC 容器,如CopyOnWriteArrayList。
// TODO 死锁代码
executor、task、stream 优先于线程 不要用 Executors 创建线程池,里面具体实现有无界队列,Integer.MAX_VALUE 等坑人的定义。无界队列会一直堆积请求,直到OOM,应该使用 ArrayBlockingQueue 这种有界队列。使用 Guava 中 ThreadFactoryBuilder 创建 ThreadFactory,而不是继承原生的(不仅麻烦,而且很多东西其实是重复的,就是为了给线程加个名字和其他一些自定义的内容),也可以用 Spring 的。
1 2 3 4 5 6 private static ThreadFactory namedThreadFactory = new ThreadFactoryBuilder() .setNameFormat("demo-pool-%d" ).build(); private static ExecutorService pool = new ThreadPoolExecutor(5 , 200 , 0L , TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>(1024 ), namedThreadFactory, new ThreadPoolExecutor.AbortPolicy());
饱和策略
AbortPolicy:中止策略是默认的饱和策略,该策略将抛出未检查的 RejectedExecutionException 调用者可以捕获这个异常,然后根据需求编写自己的处理代码。
DiscardPolicy:当新提交的任务无法保存到队列中等待执行时,抛弃策略会悄悄抛弃该任务。
CallerRunsPolicy:调用者运行(Caller-Runs)策略实现了一种调节机制,该策略既不会抛弃任务,也不会抛弃异常,而是将某些任务回退到调用者,从而降低新任务的流量。它不会在线程池的某个线程中执行新提交的任务,而是在一个调用了 execute 的线程中执行该任务。
DiscardOldestPolicy:抛弃最旧的(Discard-Oldest)策略则会抛弃下一个将被执行的任务,然后尝试重新提交新的任务。如果工作队列是一个优先队列,那么”抛弃最旧的“策略将导致抛弃优先级最高的任务,因此最好不要将“抛弃最旧的”饱和策略和优先级队列放在一起使用。
ForkJoinTask。// TODO 《Java 并发编程的艺术》解释,以及代码。Redis 子线程 Fork 父线程,进行集群同步。
并发的 Stream 是在 Fork Join 池上编写的。
并发工具优先于 wait 和 notify
Executor FrameWork
JUC 容器 ConcurrentHashMap(而不是 Collections.synchronizedMap/HashTable)
同步器 CountDownLatch,Semaphore,CyclicBarrier 和 Exchanger 等
对于间歇式的定时,始终应该优先使用 System.nanoTime 而不是 System.currentTimeMillis
// TODO Spring 同步机制代码补充
始终应该使用 wait 循环模式来调用 wait 方法,永远不要在循环之外调用 wait 方法。
一般情况下,优先使用 notifyAll 方法。// 极客时间《并发编程》代码补充
线程安全性的文档化 一个类为了可被多个线程安全地使用,必须在文档中清楚地说明它所支持的线程安全性级别。
不可变的(immutable)—— String、Long、BigInteger
无条件的线程安全(unconditionally thread-safe)—— 这个类的实例是可变的,但是这个类有着足够的内部同步。AtomicInteger、ConcurrentHashMap
有条件的线程安全(conditionally thread-safe)—— 除了有些方法为进行安全的并发使用而需要外部同步之外,和无条件的线程安全相同。Collections.synchronized 包装返回的集合。
非线程安全(not thread-safe)—— 类实例是可变的。ArrayList、HashMap
线程对立的(thread-hostile)—— 类不能安全地被多个线程并发使用,即使所有的方法调用都被外部同步包围。// TODO ThreadLocal?
使用类内部私有锁对象。lock 域应该始终声明为 final。// TODO Spring 中也是这么做的
1 private final Object lock = new Object();
慎用延迟初始化 Lazy Initialization 是指延迟到需要域的值时才将它初始化的行为。Spring Boot 中有 @Lazy 标注是否延迟初始化,如果标记了,则将会该 Bean 进行延迟初始化,只有在其他类真正使用时,进行初始化。
大多数情况下,非延迟初始化优先于延迟初始化。
如果初始化耗时长,那我们最好不要等到真正要用它的时候,才去执行这个耗时长的初始化过程,这会影响到系统的性能(比如,在响应客户端接口请求的时候,做这个初始化操作,会导致此请求的响应时间变长,甚至超时)
除非绝对必要,否则就不要这么做。
如果处于性能的考虑而需要对静态域使用延迟初始化,就使用 Lazy Initiazlization Holder Class 模式
1 2 3 4 5 6 7 8 9 public class Singleton private Singleton () private static class SingletonHolder private static final Singleton INSTANCE = new Singleton(); } public static getInstance () return SingletonHolder.INSTANCE; } }
如果出于性能的考虑而需要对实例域使用延迟初始化,就使用双重检查模式(Double-Check Idiom)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class Singleton private volatile Singleton instance = null ; private Singleton () if (instance != null )throw new RuntimeException()}; public static Singleton getInstance () if (instance == null ){ synchronized (Singleton.class ) { if (instance == null ){ instance = new Singleton(); } } } return instance; } }
Spring 中使用单例注册表(Bean 容器)控制 Bean 的单例。
有时可能需要延迟初始化一个可以接受重复初始化的实例域。可以使用单重检查模式(Single-Check Idiom)
1 2 3 4 5 6 7 8 9 private volatile FieldType field;private FieldType getField () FieldType result = filed; if (result == null ){ field = result = computeFieldValue() } return result; }
不要依赖于线程调度器 任何依赖于线程调度器来达到正确性或者性能要求的程序,很有可能都是不可移植的
如果一个程序不能工作,是因为某些线程无法像其他线程那样获得足够的 CPU 时间片,那么,不要企图调用 Thread.yield 来 “修正” 该程序。
线程优先级时 Java 平台上最不可移植的特征了。设置了优先级,不代表一定会按优先级执行,而是“看情况”。
Serialize 其他方法优先于 Java 序列化 如果使用 Java 自带的反序列化,以下层次非常高的结构,会导致系统反序列化时占用大量资源。使用 JSON 代替 Java 中的序列化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 static byte [] bomb(){ Set<Object> root = new HashSet<>(); Set<Object> s1 = root; Set<Object> s2 = new HashSet<>(); for (ini i = 0 ;i < 100 ; i++){ Set<Object> t1 = new HashSet<>(); Set<Object> t2 = new HashSet<>(); t1.add("foo" ); s1.add(t1); s1.add(t2); s2.add(t1); s2.add(t2); s1 = t1; s2 = t2; } return serialize(root); }
谨慎地实现 Serializable 接口 BigInteger、Instant 等值类应该实现 Serializable 接口,大多数的集合类也应该如此。代表活动实体的类,如线程池,一般不应该实现 Seriallizable 接口。
内部类不该实现 Serializable。
考虑使用自定义的序列化形式 跨语言的 Socket 通信,是自己实现序列化机制,包括 Redis,是以纯文本格式,换行的方式分隔操作符。
transient 表示该字段不能被序列化,当然实现了 // TODO 实现某个接口后,在方法中写明了字段,也是可以序列化的。
保护性地编写 readObject 方法 当一个对象被反序列化的时候,对于客户端不应该拥有的对象引用,如果哪个域包含了这样的对象引用,必须做保护性拷贝。
对于实例控制,枚举类型优先于 readObject // TODO 不太理解
考虑用序列化代理代替序列化实例 使用静态内部类,代理外部类序列化内容,以及反序列化。
// TODO 代码
References
关于Integer面试的一个问题
VM系列三:JVM参数设置、分析
What does AggressiveOpts do with my timings?
科普:为什么 String hashCode 方法选择数字31作为乘子
https://cloud.tencent.com/developer/article/1593982
https://blog.csdn.net/xx326664162/article/details/51743969
无声的性能杀手-伪共享(FalseSharing)
重学Java-一个Java对象到底占多少内存