大数据(BigData)三要素
“大数据”是指传统数据处理应用软件时,不足以处理的大的或者复杂的数据集的术语。
大数据是个抽象的概念,和虚拟机一样,具体实现各有不同。每个语言的实现都是不一样的,这里讲的是 Java 相关的,应用相对来说很广的大数据组件。要了解结构化/非结构化/半结构化数据、数据挖掘相关的内容,可自行搜索其他的,这里只讲部分。
大数据又称海量数据。所有的大数据相关的中间件都离不开下面三个问题。
- 如何保存海量数据
- 如何从海量数据中取有用的数据
- 以什么格式保存海量数据,高效插入和查询数据
什么上卷,下钻,slice,dice,那是 OLAP 里面的内容,Wikipedia 里面把这个搞在一起了,虽然事实上两者经常混在一起。
如何保存海量数据
GFS 登场,不要跟我说什么 RAID,不停加磁盘也是有限制的。
文件就是字节序列,仅此而已——《深入理解计算机系统》
Google File System 是 Google 发表的论文,提出了这个概念,Google 内部有实现了这个理论文件系统。Hadoop 内部实现叫 HDFS(Hadoop Distrubuted File System),其实就是加强版的文件系统。
下面是 HDFS 的总体架构图,主要是分两块
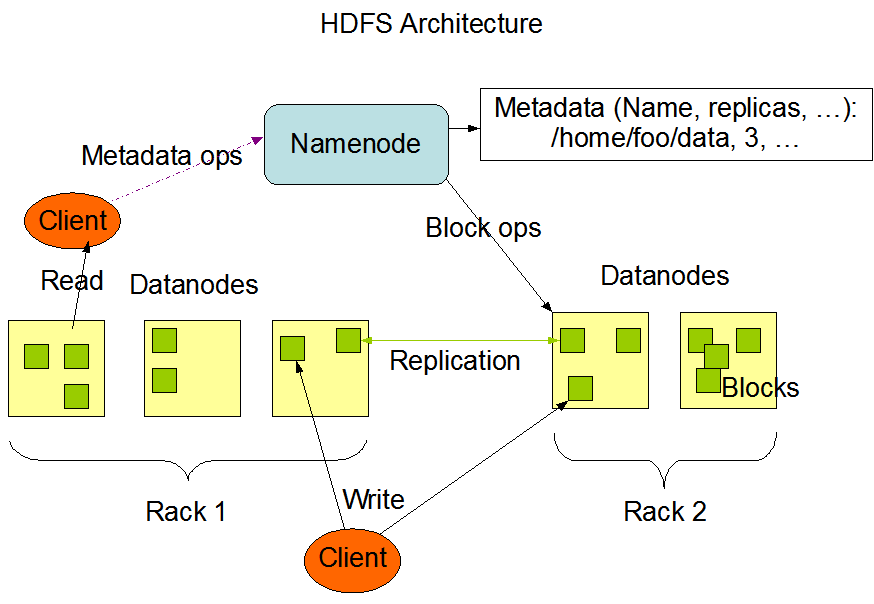
NameNode
什么是元信息?
元信息是关于信息的信息,用于描述信息的结构、语义、用途和用法等。[^1]:
我认为是最小单元信息,精简的不能再精简的那种信息,相当于句柄。
这里的 NameNode 就是部署在一台服务器上,上面保存了元(必要的)信息。例如在 HDFS 中的文件路径,文件权限信息,文件具体在哪几个 DataNode 上的信息。比如我一个存在 HDFS 上一个文件,路径是 /tmp/shaluan/aorui.log,它是一个日志文件,我通过客户端传上去的。然后元信息就有[^2]:
- 文件、目录自身的属性信息,例如文件名,目录名,能对这个文件进行 write/read/recute 等操作信息等。
- 文件记录的信息的存储相关的信息,例如存储块信息,分块情况,副本个数等。
- 记录 HDFS 的 DataNode 的信息,用于 DataNode 的管理。
NameNode 也是有主备(这里是主备,不是主从)的,保证 HDFS 高可用。
DataNode
实际保存的文件的组件。可以看作一个 NameNode 部署在一个服务器上。
数据你看上去是 TB 级别的,其实里面被分成了很多个文件块。可能是 1 GB 一个文件块,每次读取文件的时候,就读那一小块。
而且一份数据不是单独保存在一个 DataNode 的,会进行冗余,保存在多个 DataNode 上,防止一个 DataNode 挂了,然后丢失数据的情况。多个 DataNode 同时挂掉的概率不大,不考虑这种情况。
DataNode 配合上 RAID,这样数据丢失的概率大大降低了。
如何高效地从海量数据中取有用的数据
MapReduce 登场,MapReduce 既是一种编程模型,在 Hadoop 里面的实现也叫 MapReduce。
这个理解起来比较费劲,就是 映射 > 归纳。你可以看作是一条 SQL 执行过程中,执行 SQL 语法解析树的过程。Reduce 就是规约,减少的意思,其实就是类似 Group By 操作,如果你看懂了我之前写的 UDAF 文章,那个类,理解起来就比较轻松了。
可以在多个机器上,采用并行的方式,进行高效的计算。
下面就是 Mapreduce 的过程,分词 -> 映射 -> 分组 -> 归纳(减少)

实际在需要编写 Mapper 类和 Redue 类来操作数据。
详细的内容可以参考这个。
以什么格式保存海量数据,高效插入和查询数据
BigTable 登场。 BigTable是一种压缩的、高性能的、高可扩展性的,基于Google文件系统(Google File System,GFS)的数据存储系统,用于存储大规模结构化数据,适用于云端计算。[^3]:
高效插入数据,不支持删除数据,只能根据时间戳来更新数据的 NoSQL 数据库。
下面是 HBase 🐳的表结构,一个字段只有时间戳、RowKey(关系数据库中的 id)和 col(关系数据库中的字段,什么 deleted,create_date这种)。然后映射表(实际取数据的表,映射成行式数据库)就是根据实际的 rowkey 和 col(字段)映射出来易于理解的关系型数据库类型的表。注意这个 ps 下的 ps 的1234 和 5678,他这个 t16 比 t02 晚,所以取最新的数据。HBase 不会删数据,只会取最新的数据。

在实际生产中,一般也就一个列族,RowKey 等长,不是特别长的 RowKey 等等设计,原因可以看《HBase 原理与实战》这本书。
管理
Zookeeper 集群信息管理
这么多东西,全是一主多从的架构方式,让谁管理?Zookeeper 就登场了。
Zookeeper(动物管理员)为什么叫动物管理员,和上面的 HBase(🐳)Hadoop(🐘)以及下面的 Hive(🐝)Pig(🐷)有关。全是动物 logo,管理这些动物信息,能不叫 Zookeeper 吗。
用于管理主从信息,以及主从选举,如果从节点掉了,剔除从节点,保证高可用的中间件。ZooKeeper曾经是Hadoop的一个子项目,但现在是一个独立的顶级项目。[^4]:
当然 Zookeeper 也是一主多从架构。一个 Leader 多个 follower。
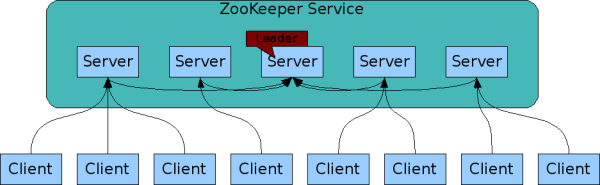
也是以文件形式保存信息的,一切皆文件。例如 /ids/broker/olap01,然后这个节点保存了很多信息,什么时间,ip 地址都可以塞进去。
主要分两种节点,细分是 4 种。
- 持久化节点
- 临时节点
第一个永久保存的,第二个客户端连接的时候有,session 断了就没了。
Yarn 资源管理
其实很多组件的一部分都是在一台机器上的,比如 Zookeeper 的一个 follower 在服务器 A 上,HDFS 的 DataNode 也在,HBase 的 HMaster 也在。计算机资源(cpu 算力,内存容量等等)是有限的,所以要通过一个组件来调度这些组件合理的利用服务器资源。

降低开发难度
哦,每次我要统计的时候,我都要写 Mapper 和 Reducer 函数,累不累?那些数学好,编程一般的,怎么做数据分析?有没有更简单的方式来搞?
Hive 和 Spark SQL 登场了。
Hive🐝
Apache Hive是一个建立在Hadoop架构之上的数据仓库。它能够提供数据的精炼,查询和分析。[^5]:
上面的解释太官方了,其实就是你写 SQL,Hive 帮你把 SQL 转换成对应 MapReduce 任务,让你更方便查数据而已。
和一般规范的 SQL 没差,就是 insert into table(这里要加个 table 关键字)tableName,还有 UDAF 中不能嵌套其他方法,例如 select myudaf(avg(x),avg(y)) from xxtable group by x;
Hive 上不存数据,数据存在 HDFS 上,有比较多的数据格式存储。例如存成 Text、CSV、ORC、Holodesk等。数据是像下面这样存的。
employee.txt 这里面就以换行作为分隔符,也有用 \t 作为分隔符,分离成数据的。结合上面的 MapReduce 图就能看懂了。也可以用 | 作为分隔符,怎么舒服怎么来。
1 | 1,Alice |
1 | DROP TABLE IF EXISTS employee; |
| Id | Name |
|---|---|
| 2 | Bob |
| 1 | Alice |
下面是 Hive 的 JDBC URL。Hive2 协议解决了 Hive 协议的一些bug,所以现在用 Hive2 协议。
1 | jdbc:hive2://127.0.0.1:10000/xxx --maxWidth=1000 |
Pig 🐷
Pig是一个基于Apache Hadoop的大规模数据分析平台,它提供的 SQL-LIKE 语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。Pig 为复杂的海量数据并行计算提供了一个简单的操作和编程接口,使用者可以透过Python或者JavaScript编写Java,之后再重新转写。
和 Hive 功能差不多,就是把特定的语言转换成 MapReduce 运算,只是不是用 SQL 这种语言。
SlipStream/Flink
也是 SQL,简化开发,上面的 Hive 只能是说作为离线数据,进行批处理。这两个组件,前者是 TDH 内置的流处理组件,后者 Flink 是阿里等大型企业推荐并提交源码的流处理组件。
什么是批数据?
有界流数据。
利用 Sqoop 可以做定时任务,每天在业务低谷期,从线上关系型数据库中抽取数据到 HDFS,可以用做离线数据分析等。
你可以把 Sqoop 想象成抽水机,数据(水)在不同数据库(水源)中,抽到 HDFS 中,然后 Hive 可以从 HDFS “导入”数据。
下面是 Sqoop 的一个用法。
1 | sqoop import --append --connect jdbc:mysql://localhost:3306/mall --username root --password 123456 --target-dir /long/sqoop --m 1 --table goods --fields-terminated-by '\t'; |
什么是流数据?
无界流数据。
比如 SlipStream (TDH 内的组件)就是创建表的时候绑定 Kafka 的某个 Topic,源源不断的从该 Topic 读取数据。避免上游数据量过大,消费不过来,从而需要反压机制(这个在另一篇介绍数据仓库的文章会提到)。
TDH 很多银行在用,对标的是国外知名的 CDH,就是贡献那个有 Cloudera Kafka 的。
为什么要这么处理?
可以求线性回归方程相关系数,来确定两个字段的相关值,进而做一系列的数据分析。
像下面这样,搜索量和票房的关系。

S 赛的 KI 上校(就是肯德基那个),是通过大量的离线数据(过去的大量玩家的比赛记录)分析 + 实时数据分析(当场比赛数据) => 推导出胜负曲线。狭义的数据分析分三块,现状分析、原因分析、预测分析,S 赛的 KI 上校就是先现状分析 –> 原因分析 –> 预测分析。
CDH/TDH
CDH
Cloudera Data Hub
TDH
Transwarp Data Hub
TDC
Transwarp Data Cloud
大数据就业方向
数据分析
数据科学研究
数据科学家是一个全新的工种,能够将企业的数据和技术转化为企业的商业价值。随着数据学的进展,越来越多的实际工作将会直接针对数据进行,这将使人类认识数据,从而认识自然和行为。Deep Learning、Machine Learning。
数据预测分析
营销部门经常使用预测分析预测用户行为或锁定目标用户。预测分析开发者有些场景看上有有些类似数据科学家,即在企业历史数据的基础上通过假设来测试阈值并预测未来的表现。
这是你们以为的大数据开发。
数据应用开发
数据仓库
为方便企业决策,出于分析性报告和决策支持的目的而创建的数据仓库研究岗位是一种所有类型数据的战略集合。为企业提供业务智能服务,指导业务流程改进和监视时间、成本、质量和控制。
报表 + 多维度数据库联机查询。做报表的。
数据安全研究
数据安全这一职位,主要负责企业内部大型服务器、存储、数据安全管理工作,并对网络、信息安全项目进行规划、设计和实施。成都加米谷大数据培训机构,专注于大数据人才培养。
说白了,大数据运维 + 安全管理员。一站式大数据平台就是降低大数据运维和应用难度的,例如 CDH、TDH、阿里的飞天大数据平台。
企业数据管理
企业要提高数据质量必须考虑进行数据管理,并需要为此设立数据管家职位,这一职位的人员需要能够利用各种技术工具汇集企业周围的大量数据,并将数据清洗和规范化,将数据导入数据仓库中,成为一个可用的版本。
下面是用 Kafka Streams 这种类型的做数据清洗和规范化大概的图。有三个系统,每个系统往不同的 topic 发消息,格式不同,然后数据清洗应用根据不同 Topic 设置不同规则,对数据进行清洗和规范化。当然这个数据清洗还可以做聚合运算等操作,将信息重新梳理,然后发给其他 Topic。
注:Kafka Streams 是一个非常非常非常基础的内容,很多东西你做不到配置即用,编写 SQL 就能跑起来这种境地,所以不建议在生产上直接使用 Kafka Streams 。

信息架构开发
大数据重新激发了主数据管理的热潮。充分开发利用企业数据并支持决策需要非常专业的技能。信息架构师必须了解如何定义和存档关键元素,确保以最有效的方式进行数据管理和利用。信息架构师的关键技能包括主数据管理、业务知识和数据建模等。
数据中台构建。
OLAP开发
OLAP在线联机分析开发者,负责将数据从关系型或非关系型数据源中抽取出来建立模型,然后创建数据访问的用户界面,提供高性能的预定义查询功能。
我这边就是和这个相关的,也和下面的研发沾点边,因为 HBase 和 Hive 没有提供健全的 HTTP 接口查询。目前只支持单表查询,以及 HBase 单表查询,并且采用 Fail-fast 原则,采用 FutureTask,必须在 6s 内返回结果,不至于一个查询拖垮整个链路调用,不至于其他系统调用我们的 Dubbo 服务出现问题。当然也解决了部分的 Spring boot data HBase 相关调用缓慢的问题。有点中间件的味道
数据系统研发
二次开发 Hadoop 组件
或者直接开发一套解决大数据内容的中间件,用 Solr 或者 Elasticsearch 增强 HBase 这种。
可视化工具开发
可视化开发就是在可视化工具提供的图形用户界面上,通过操作界面元素,有可视化开发工具自动生成相关应用软件,轻松跨越多个资源和层次连接所有数据。过去,数据可视化属于商业智能开发者类别,但是随着Hadoop的崛起,数据可视化已经成了一项独立的专业技能和岗位。
光有 Hadoop 可不行,还需要可视化的内容,去更加方便操作里面的组件。[^6]:
Colossus
GFS升级版
[3]:BigTable 维基百科
[4]:Zookeeper 维基百科
[5]: Hive 维基百科